
Eliminate ticket ops
Ticket ops is draining your organization. Keeping Ops teams busy with unproductive work hinders velocity and negatively affects lead time.
100%
less waiting times for devs
75%
reduction ops overhead
95%
fewer config files











Automate and standardize workflows

Minimize dependencies on ops

Improve ops per dev ratio








SEE it in action
Top performing orgs don’t write tickets









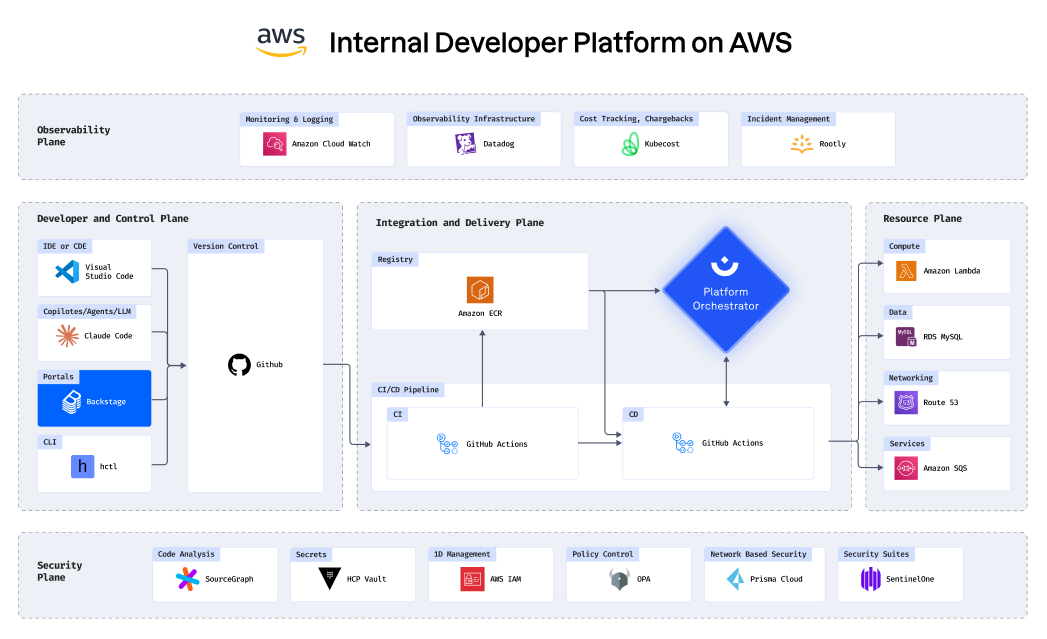
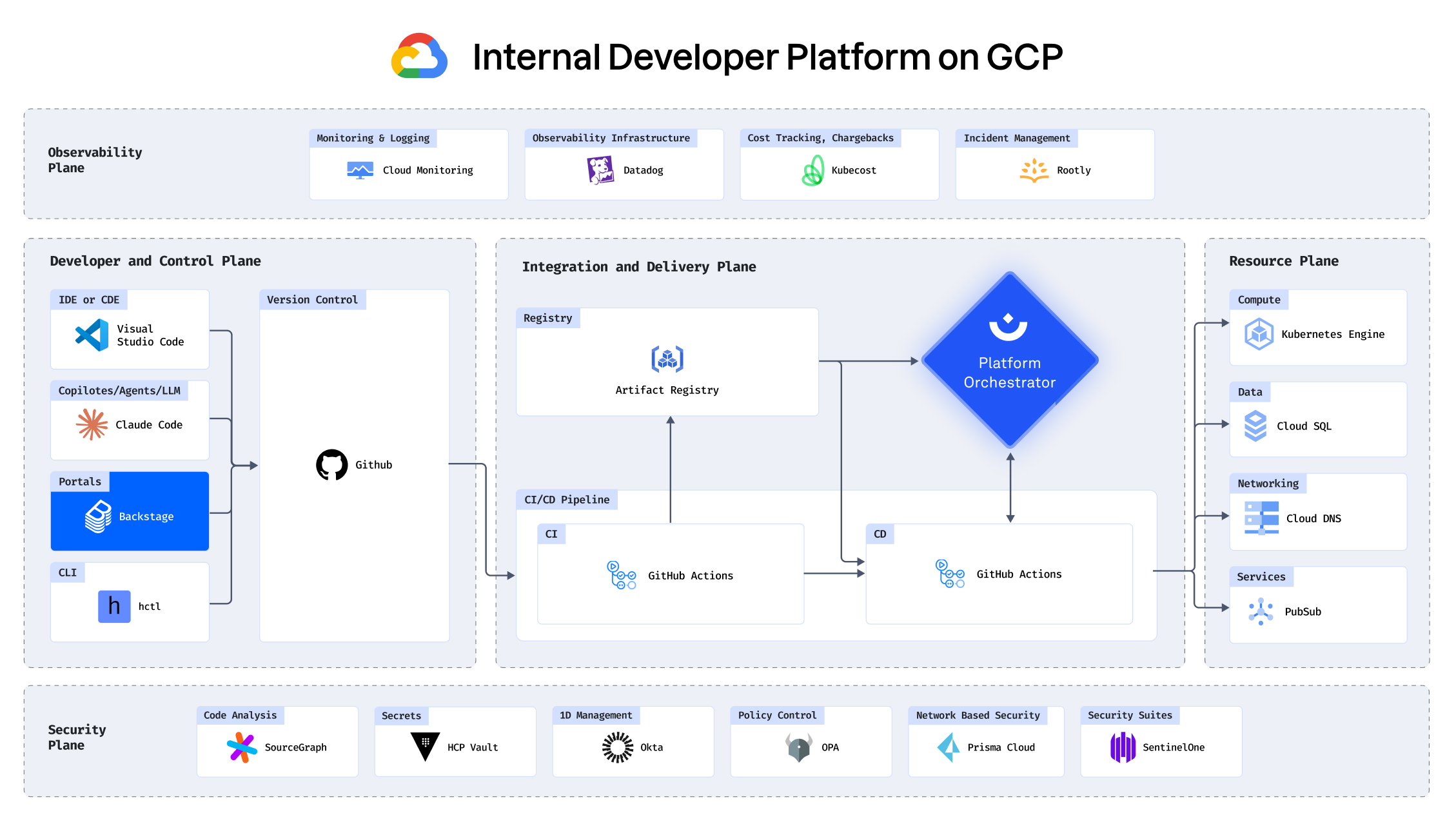
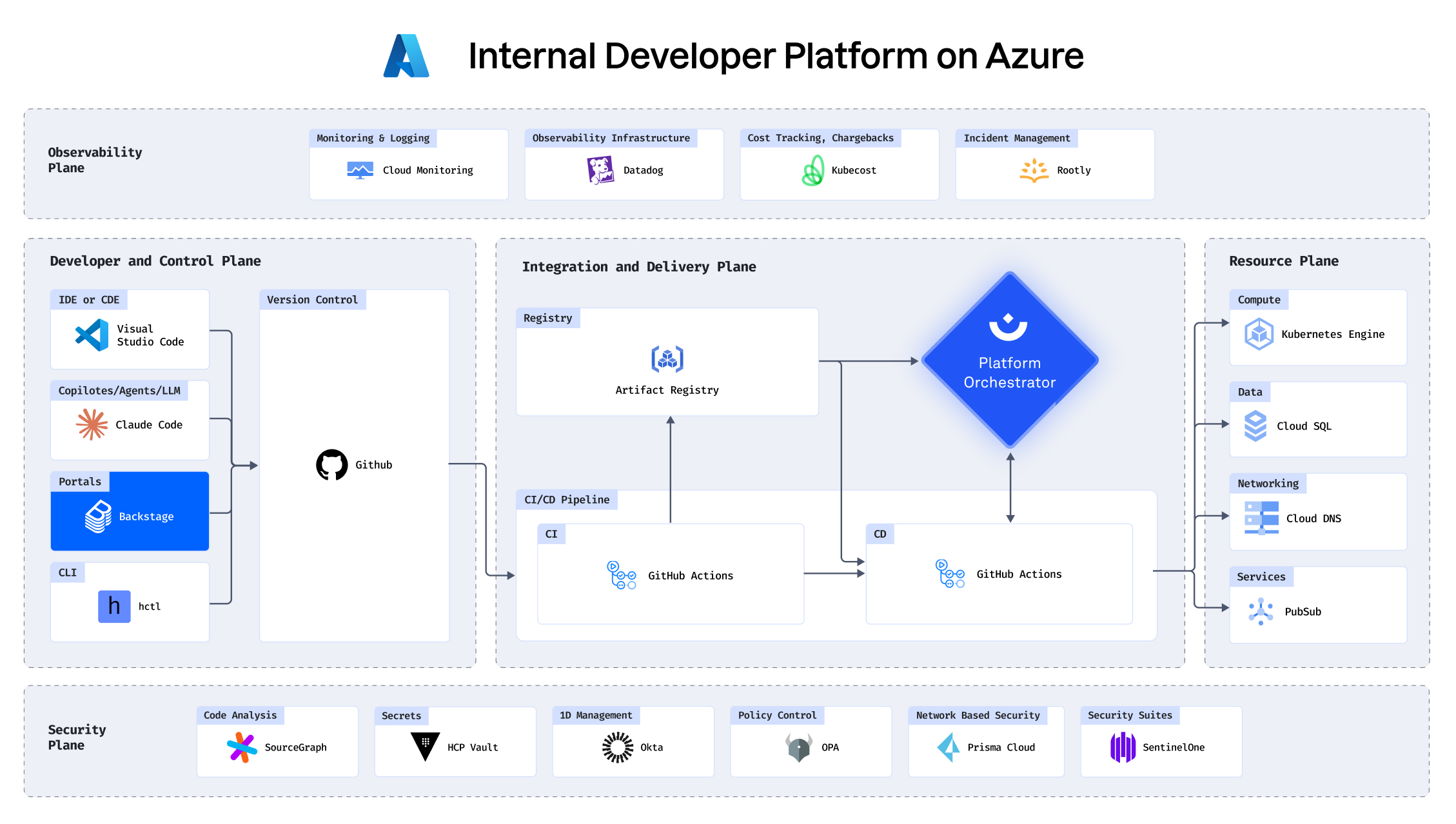
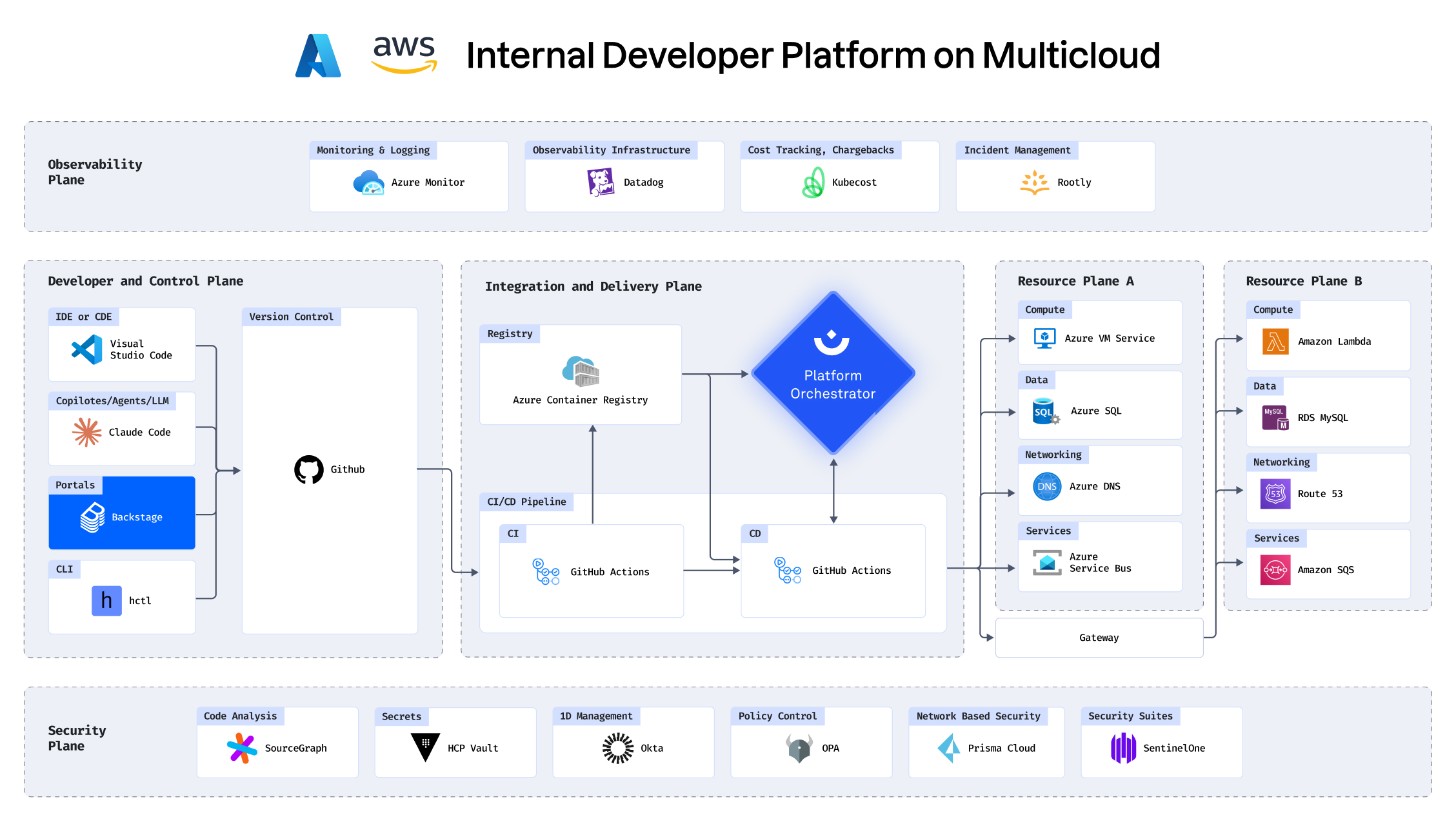


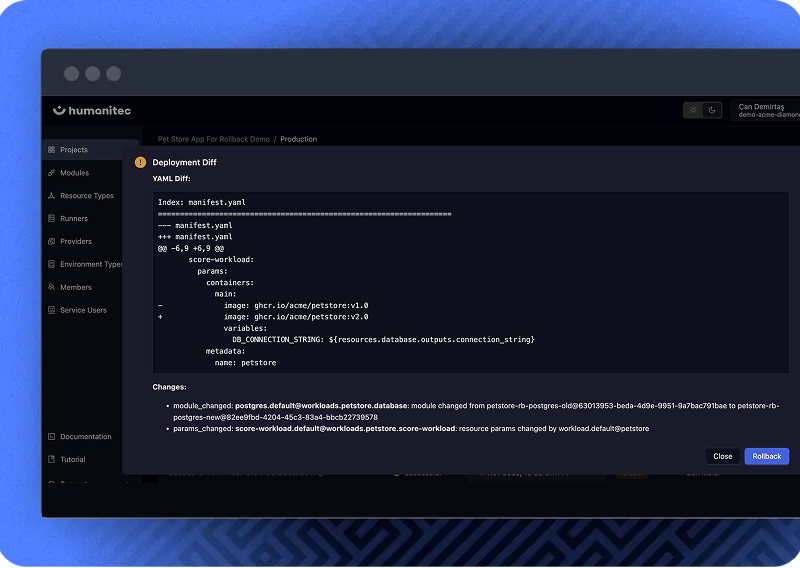
Know exactly what you’re rolling back

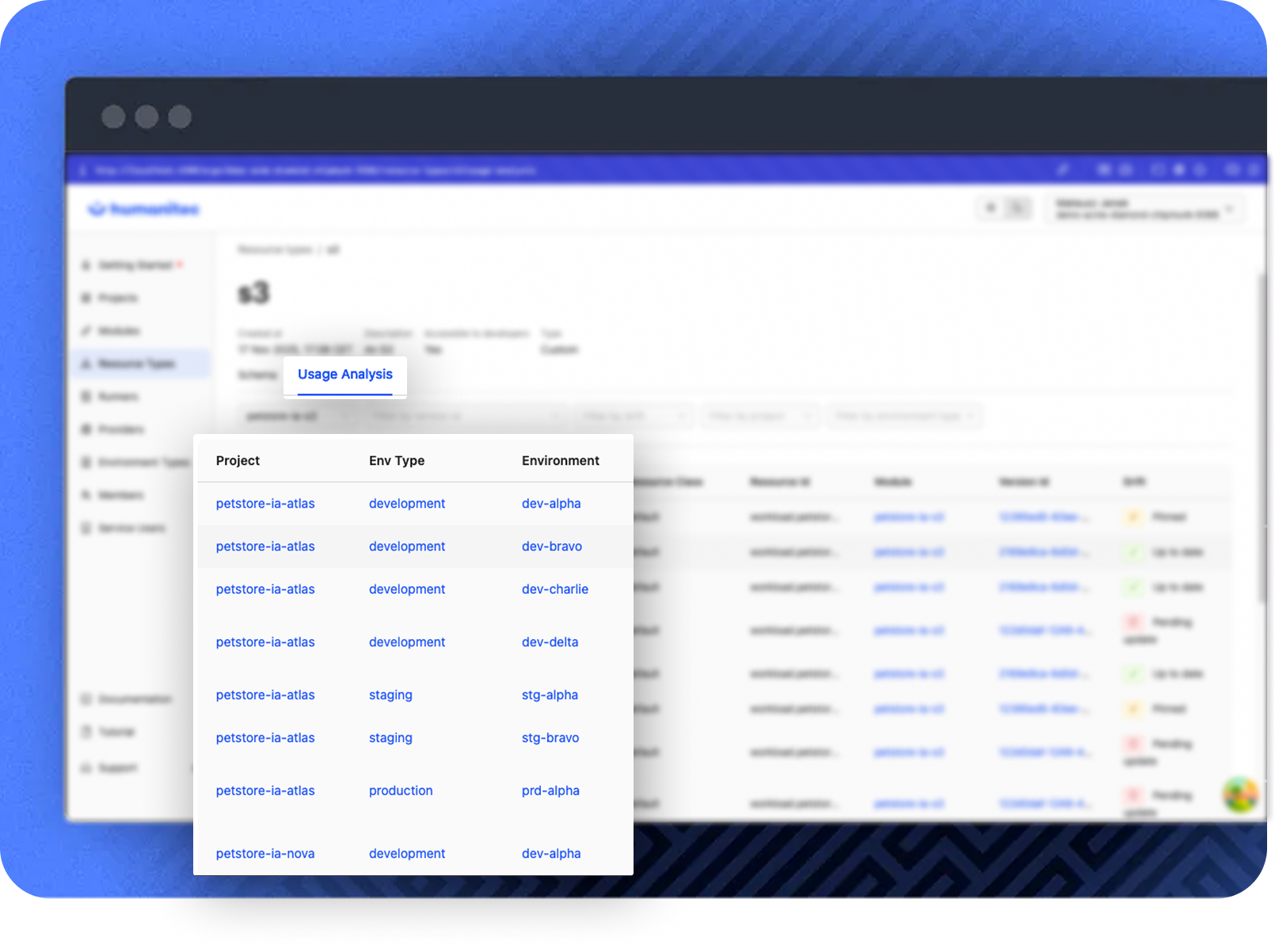
No more guessing who’s affected

HOW IT WORKS
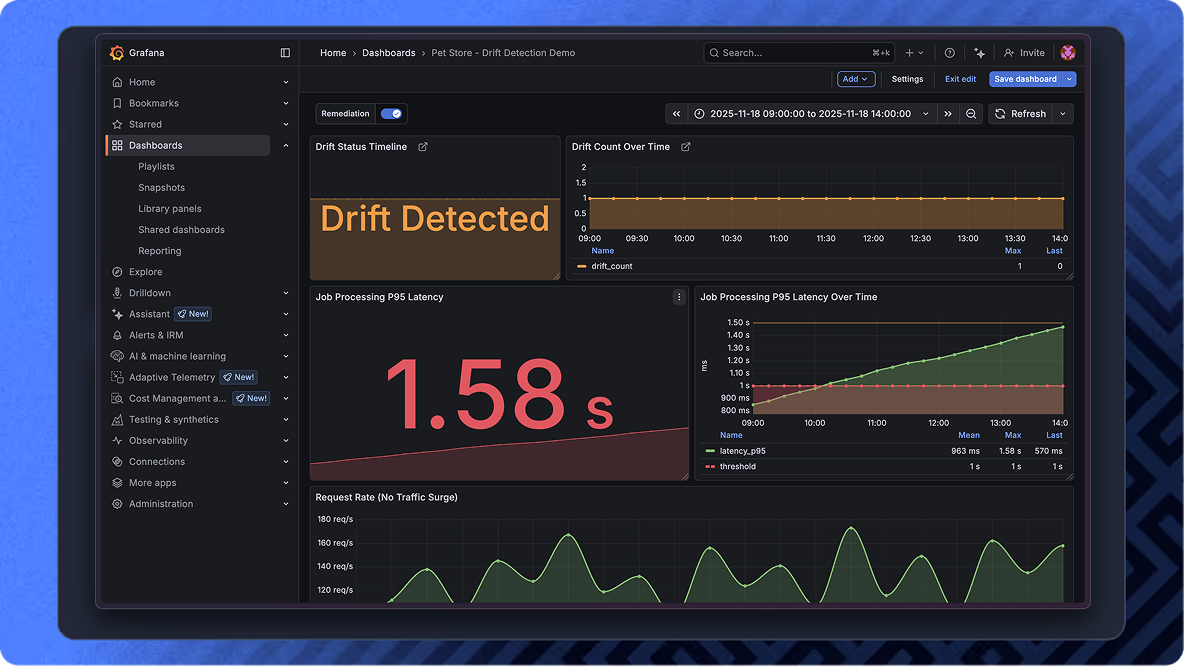
See drift. Understand it. Fix it.
Catch drift where you already monitor your systems
observability stack, so teams see issues
immediately.

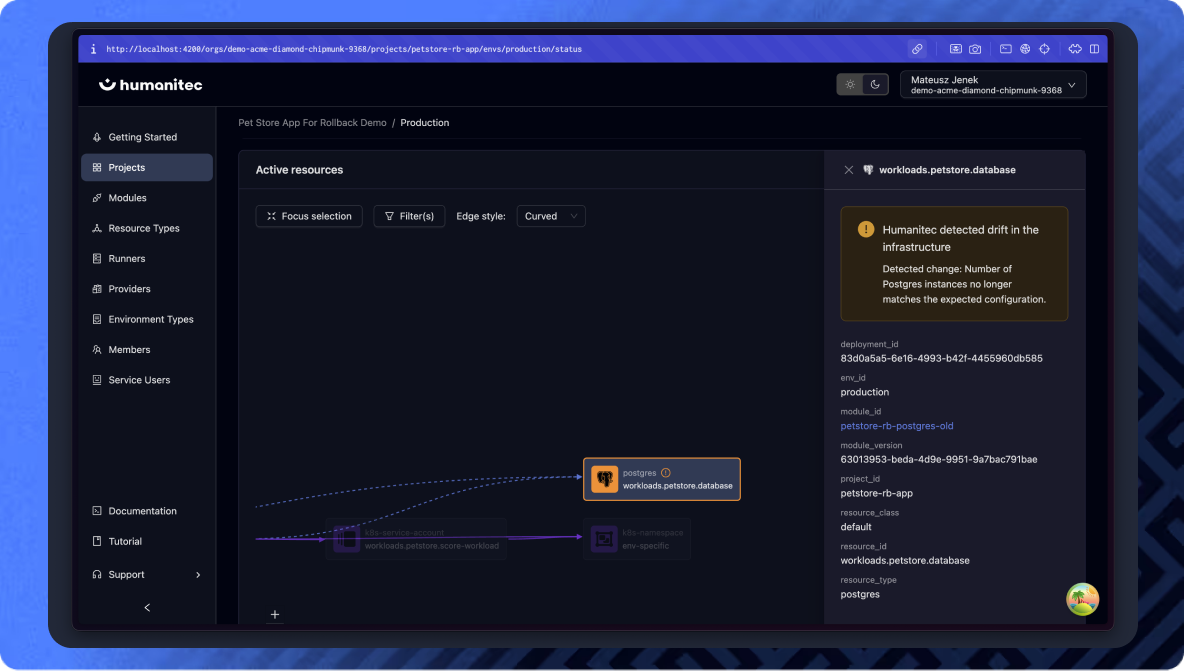
Know exactly what’s affected
environment are out of alignment
See precisely what changed
node and configuration causing the drift, so teams
can resolve the issue fast and confidently.
Today
vs
with Humanitec
Today
vs
with Humanitec
Today
vs
with Humanitec
Today
vs
with Humanitec
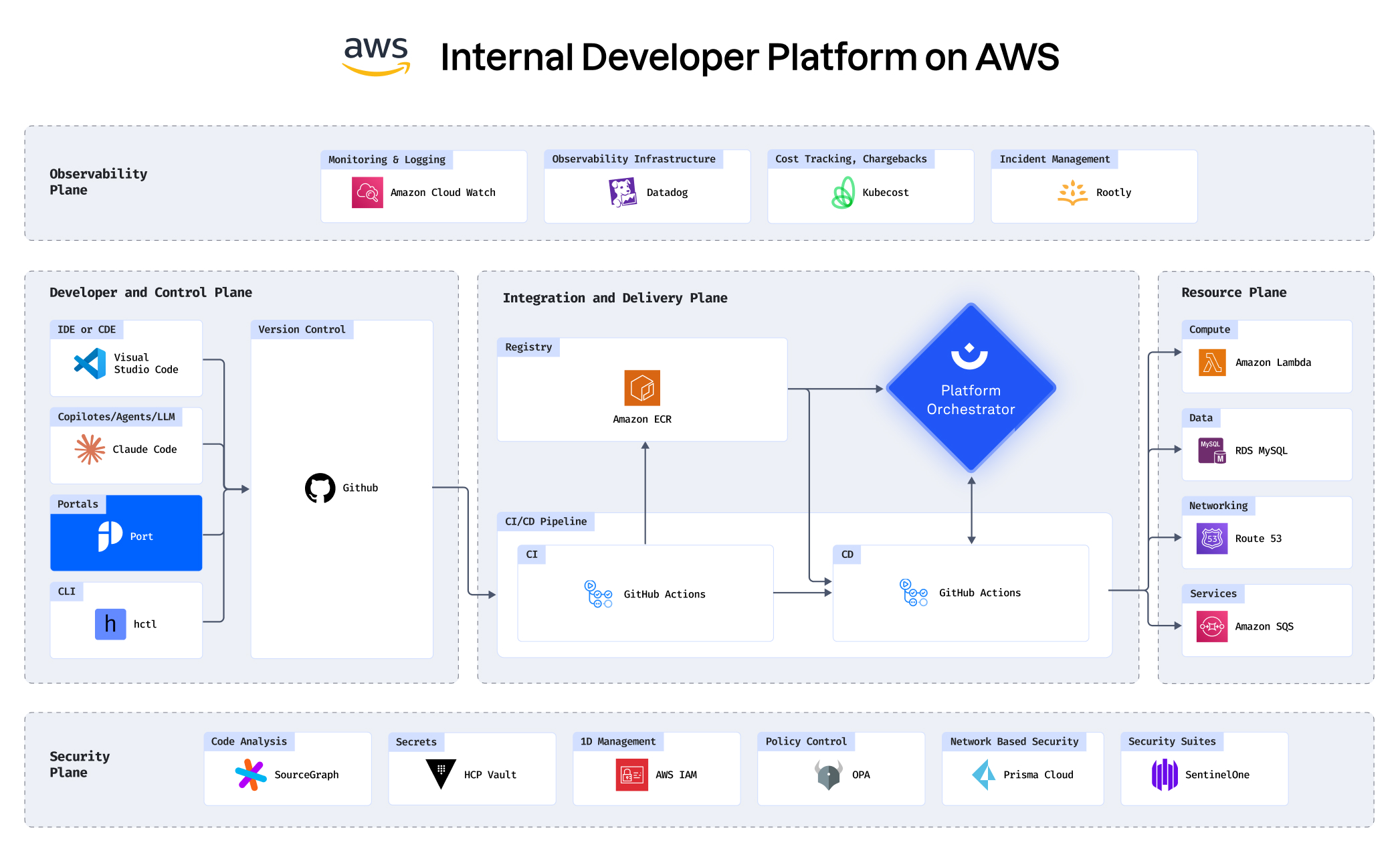
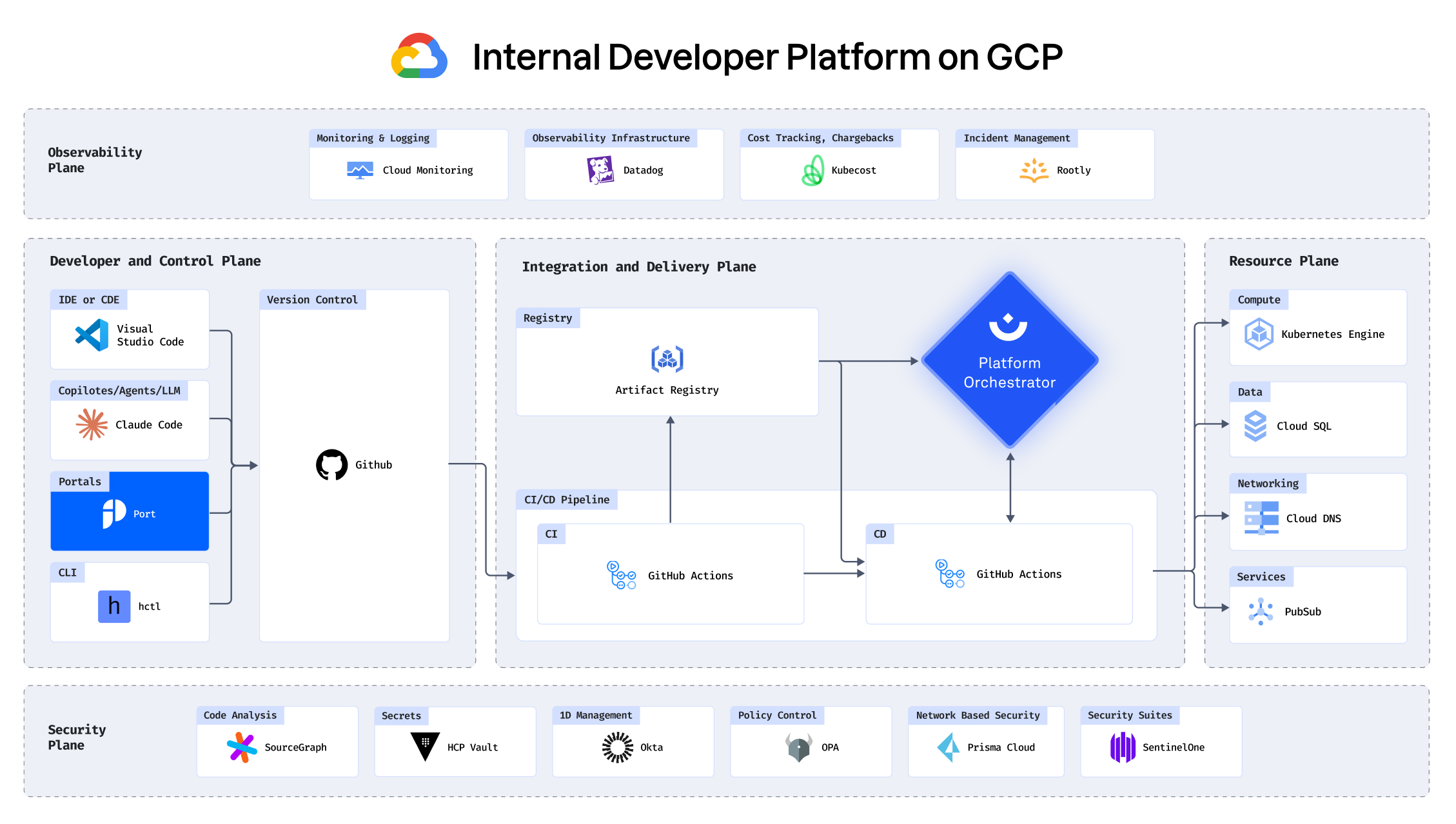
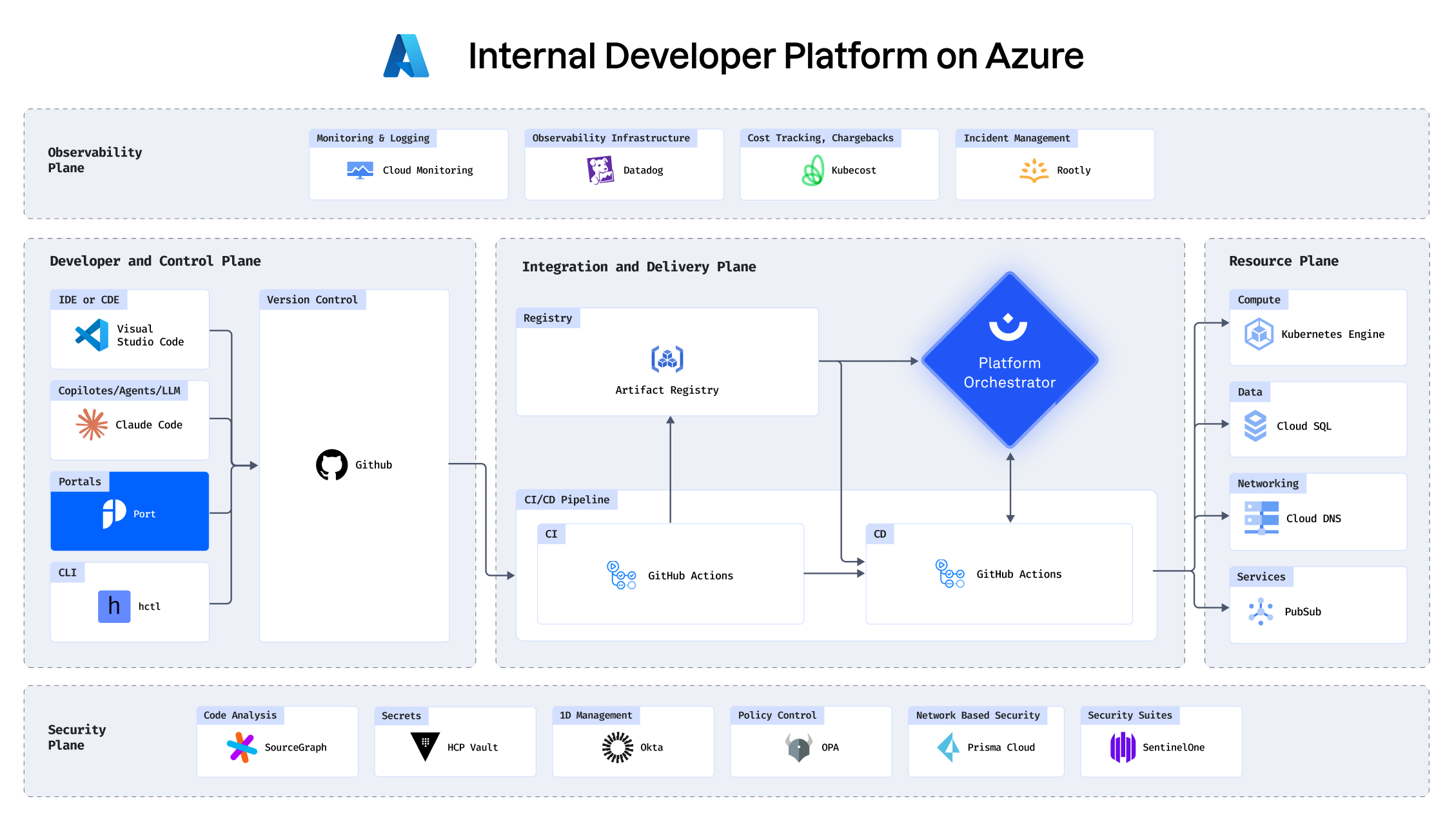
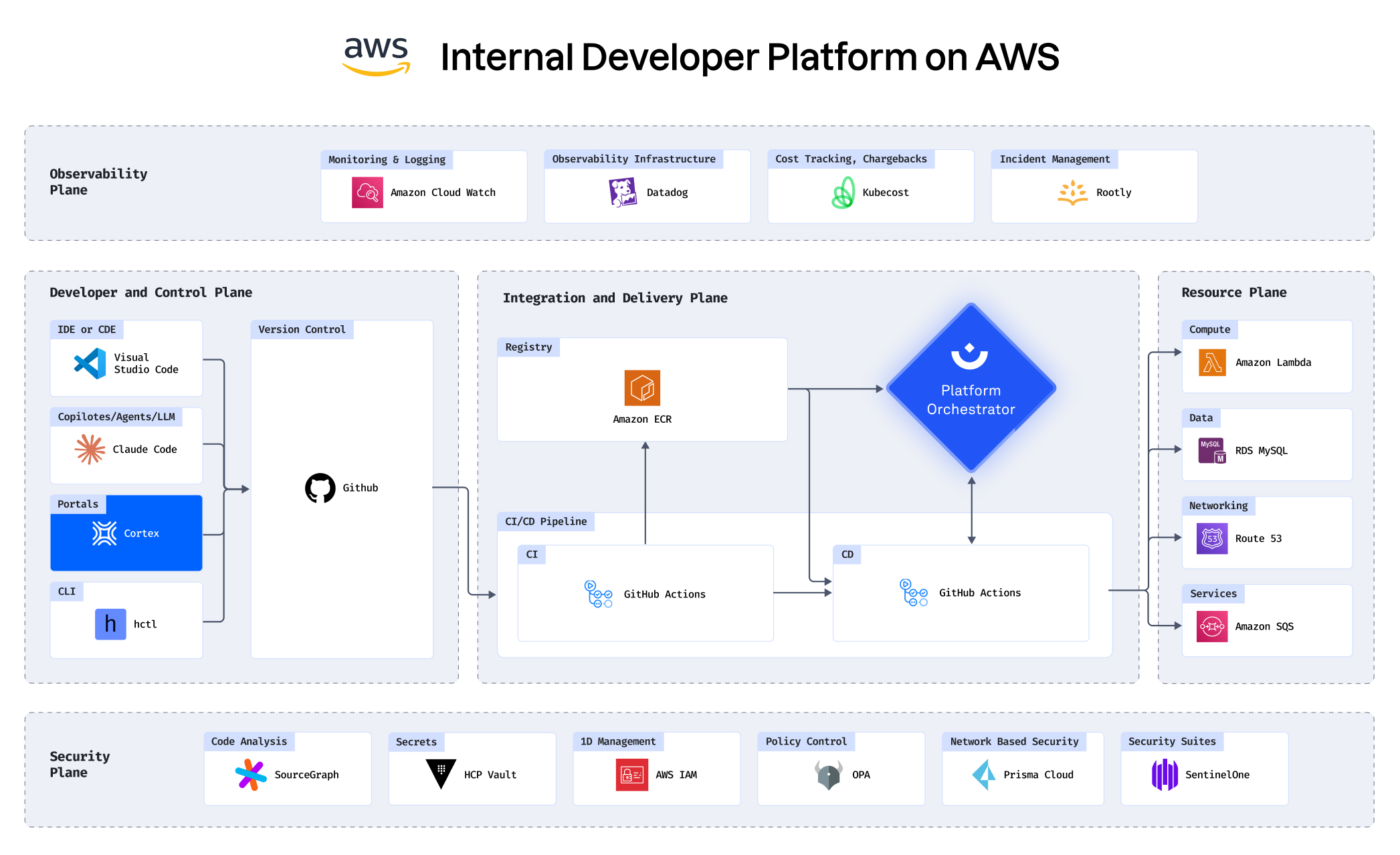
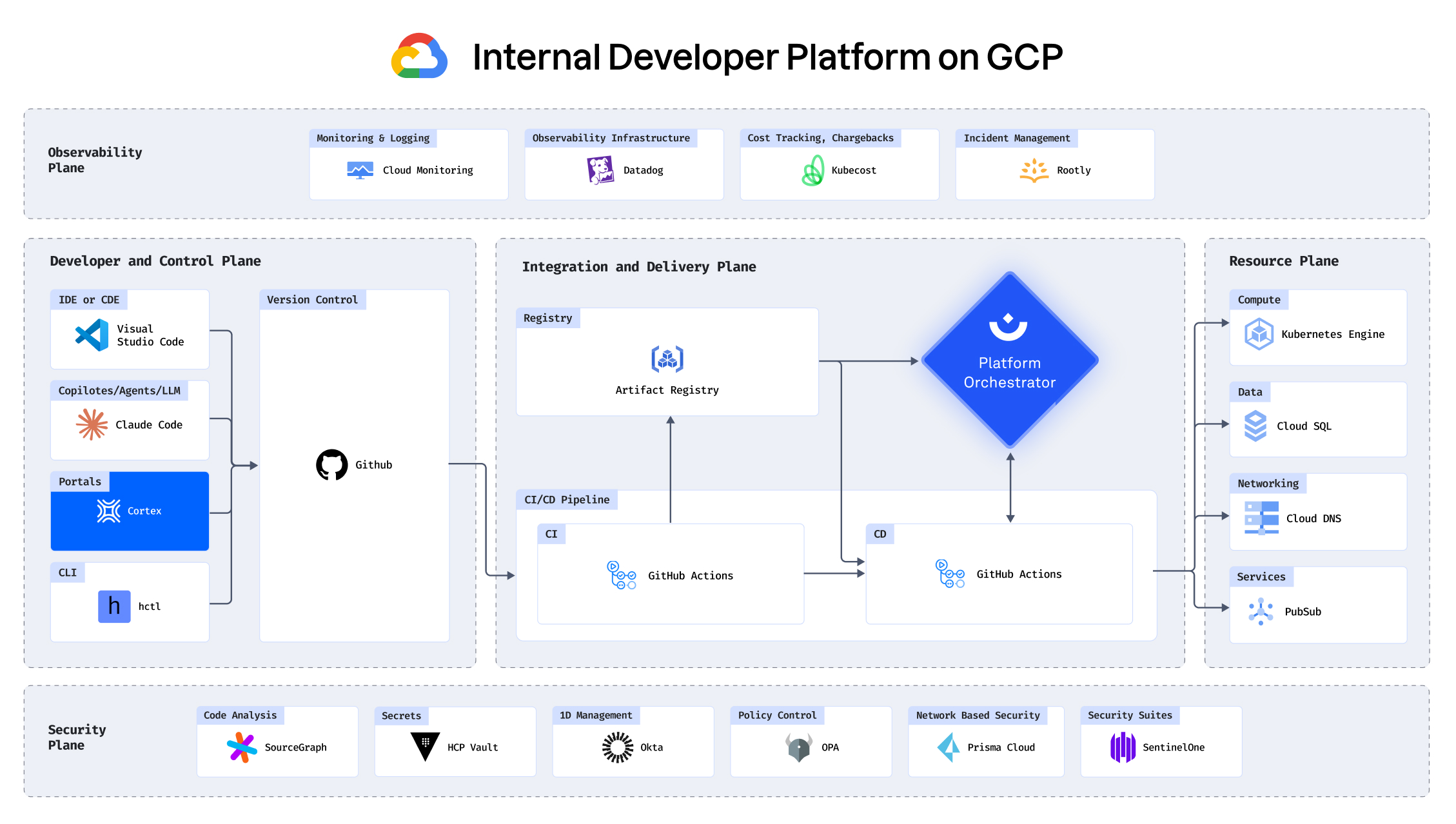
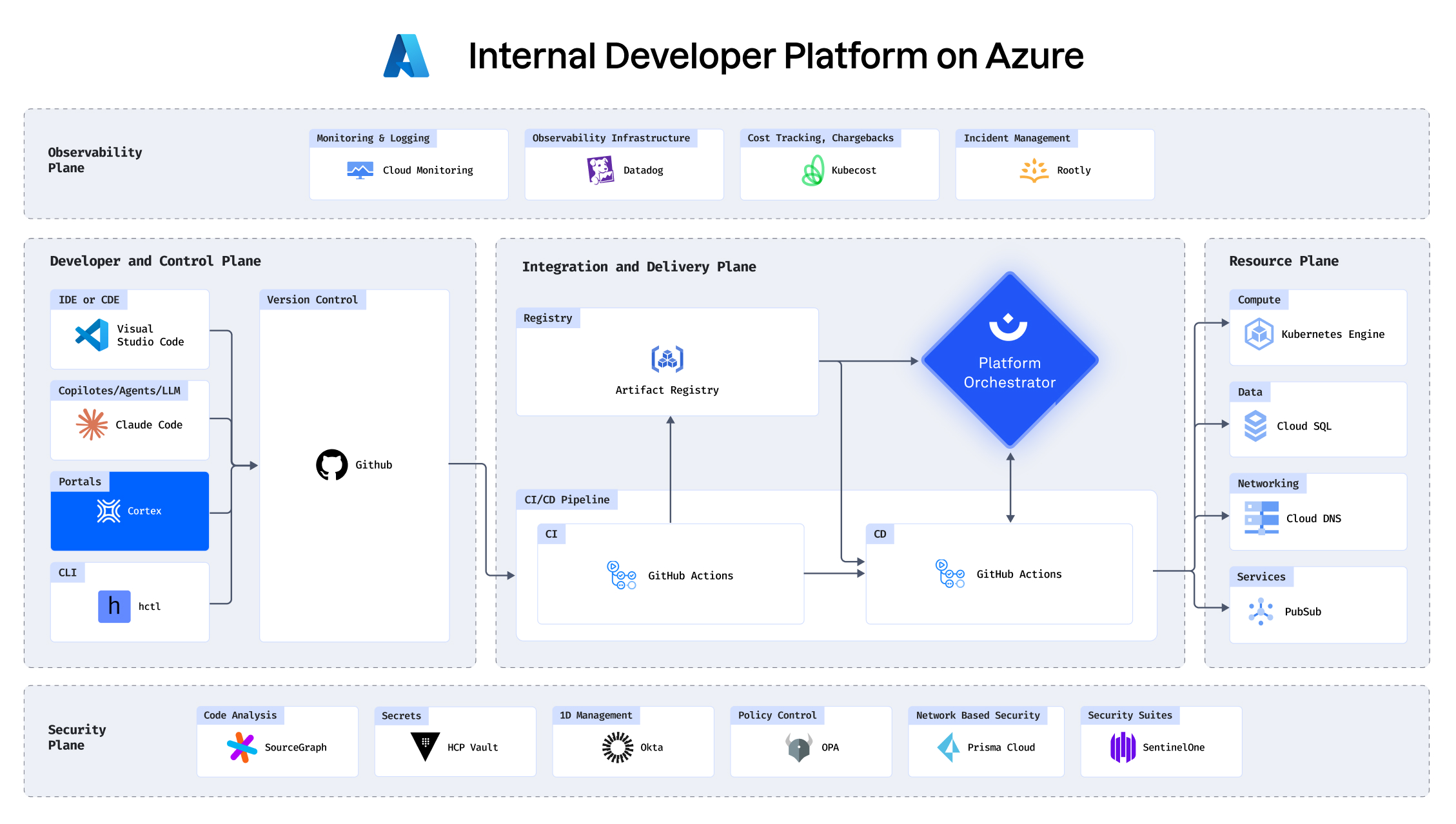
See how you can build an IDP in under 30 minutes
Building an IDP using GCP, Port, Humanitec, Datadog and
more
Building an IDP using AWS, Cortex, Humanitec, Datadog and
more
See how you can enable developer self service in 5 minutes:
See how Convera reduced ops dependencies with Humanitec
Before Convera built their IDP with Humanitec, the flow from commit to production was tedious and time-consuming. Lots of manual configuration was required and developers constantly had to wait for Ops support.
Now developers self-serve what they need and can work on shipping features instead of config files. Ops can focus on valuable tasks rather than fighting repetitive tickets.
.webp)
Humanitec has helped us accelerate our modernization journey. Thanks to the Platform Orchestrator our developers can self-serve everything they need to be productive. Humanitec allowed us to streamline our operations without compromising on quality or security.

Dive deeper

