
Know exactly what breaks — before it breaks everything
When a shared module is faulty, the Platform Orchestrator reveals the full blast radius instantly, showing affected workloads, environments, and owners—no guesswork required.


















SEE it in action
How
When a shared module is wrong, teams rarely know how far the impact spreads. The Orchestrator reveals the full blast radius instantly—affected environments, workloads, and owners—so platform teams can target fixes, roll out updates safely, and stay compliant.
See it in the demo below
See a short demo in the video below:
Each wave is fully controlled. You see progress clearly, validate behavior using your existing observability tools, and stop or roll back instantly if something looks off. Blast radius stays small. Production stays safe. And platform teams ship infra updates without fear of widespread outages.









Using portals:
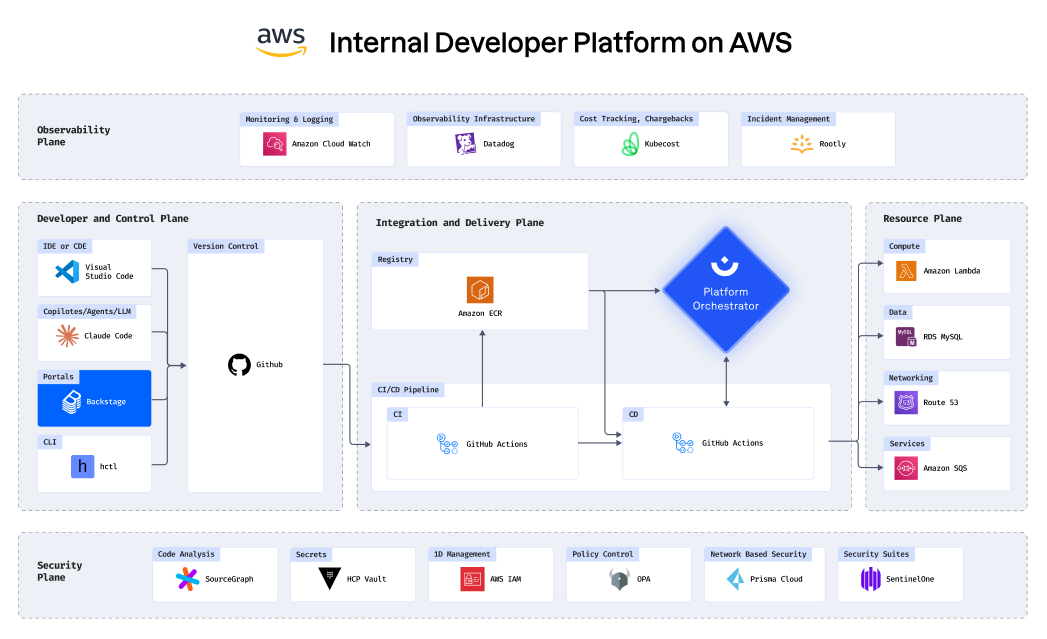
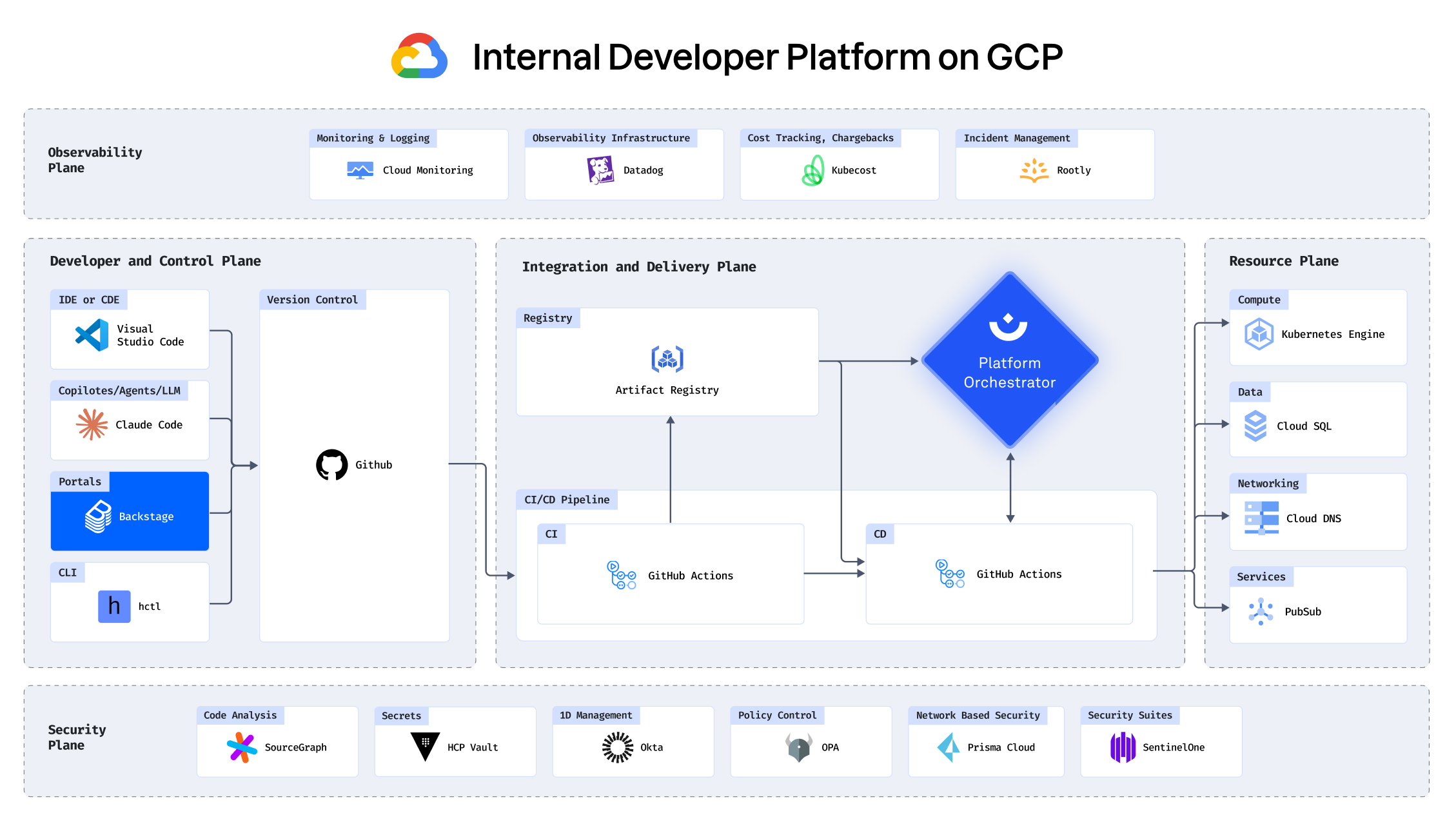
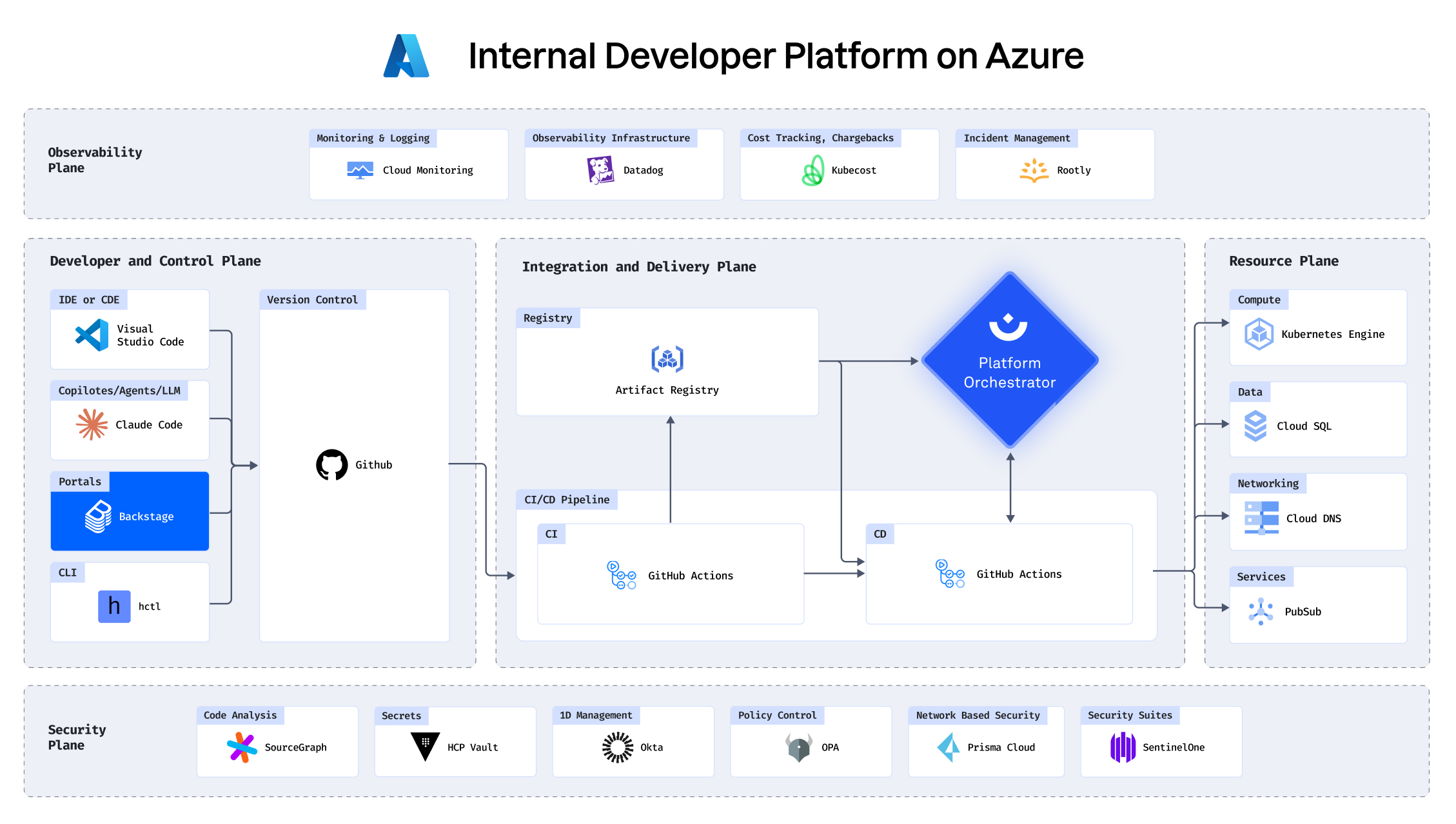
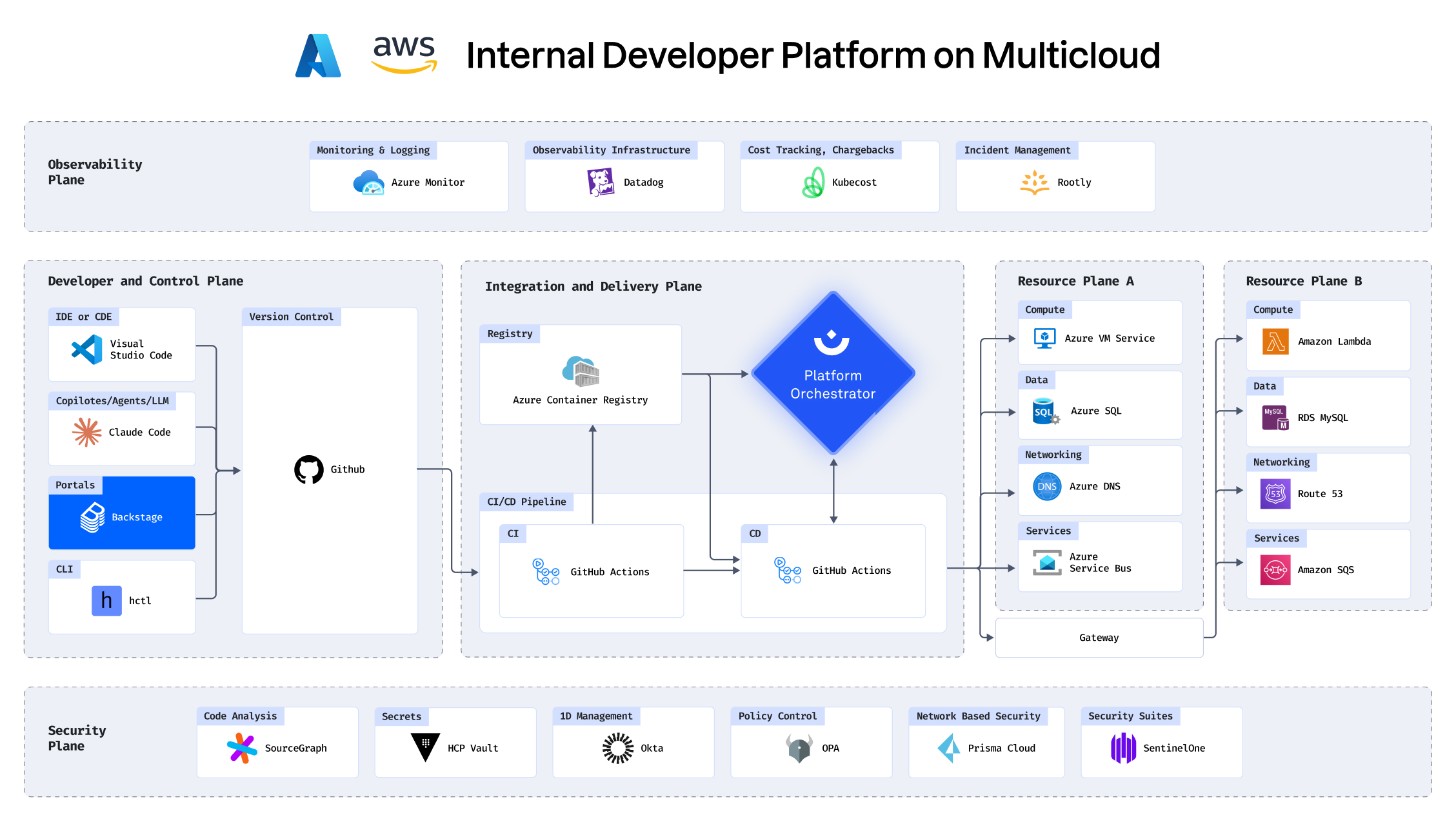
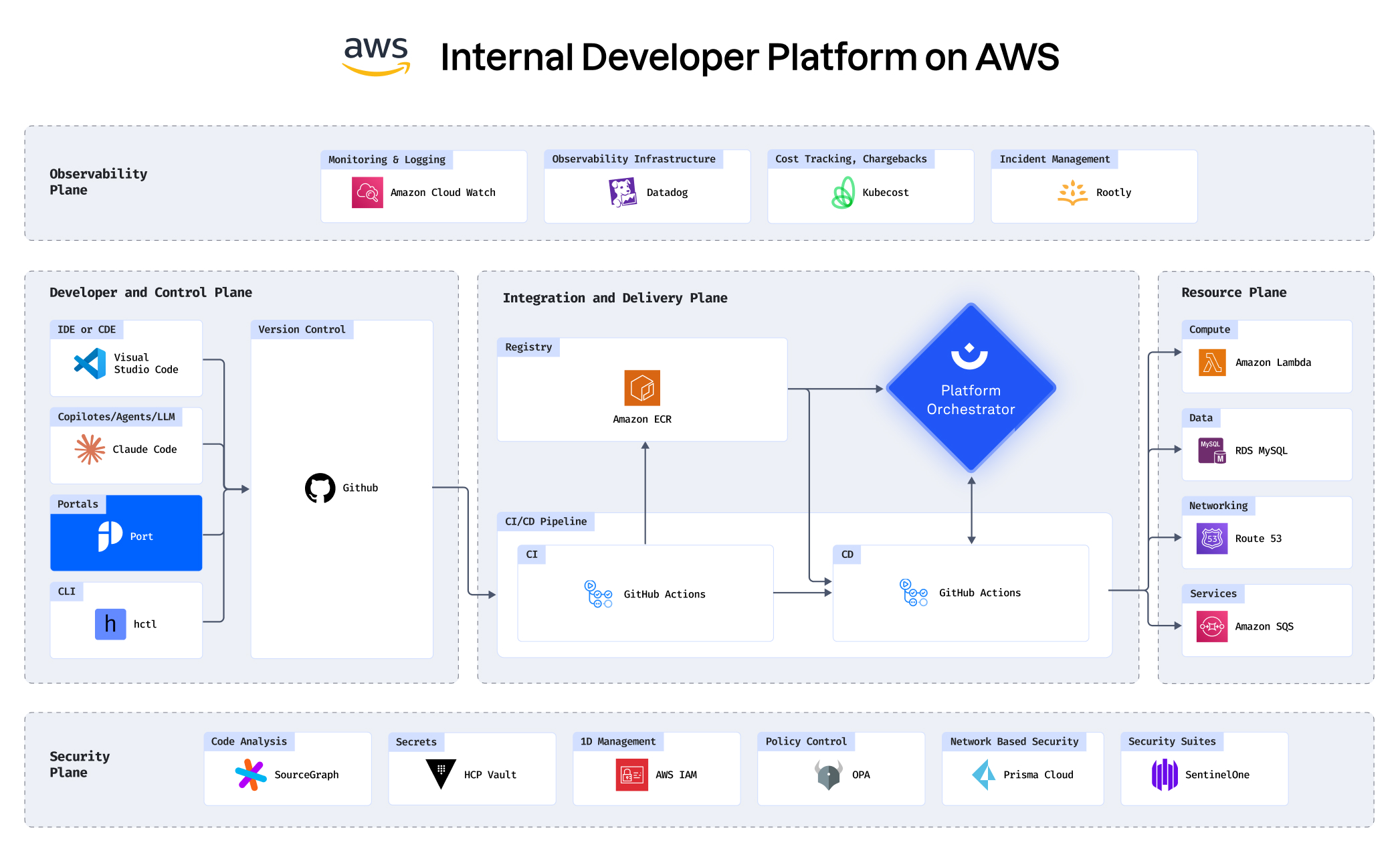
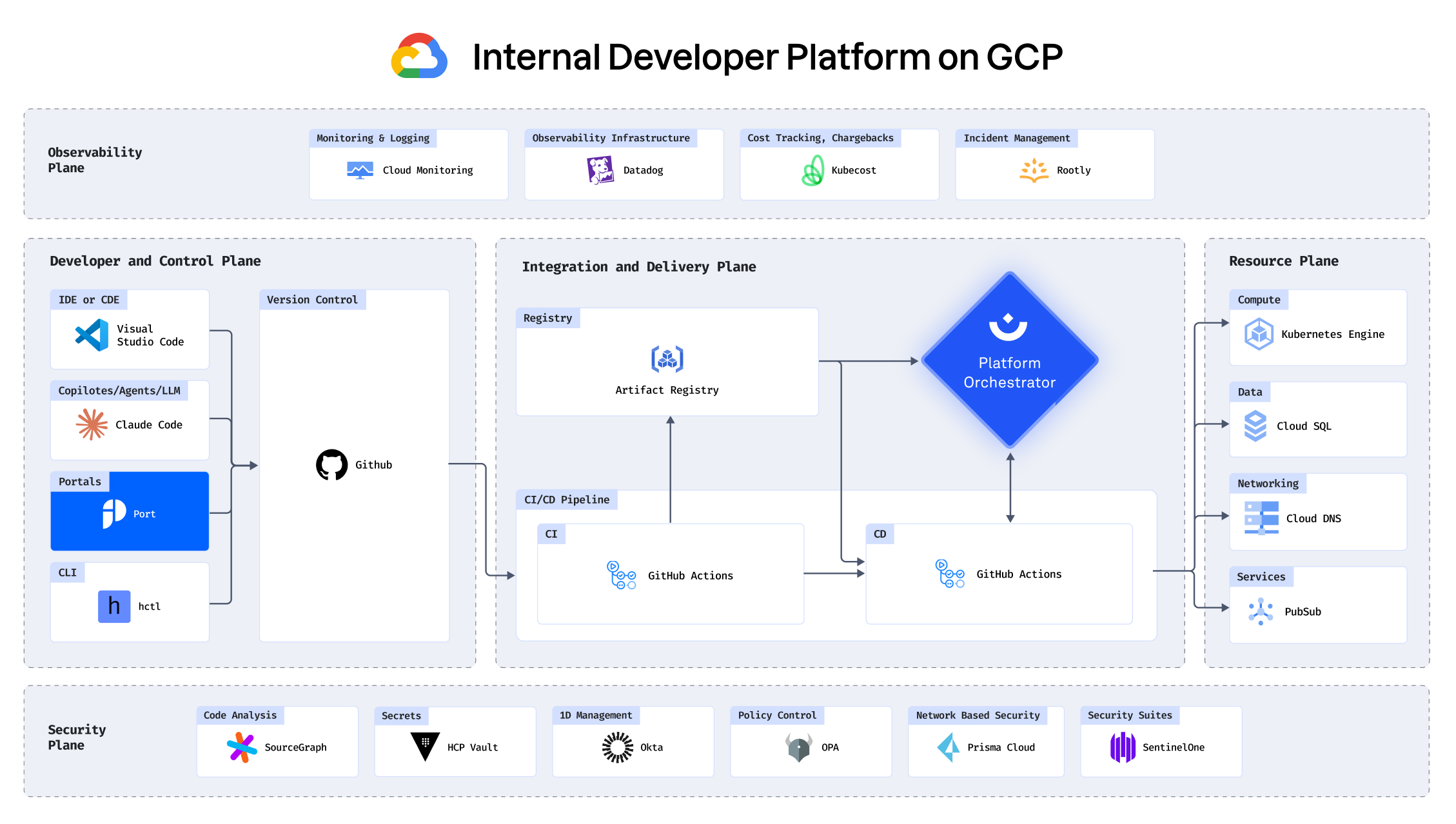
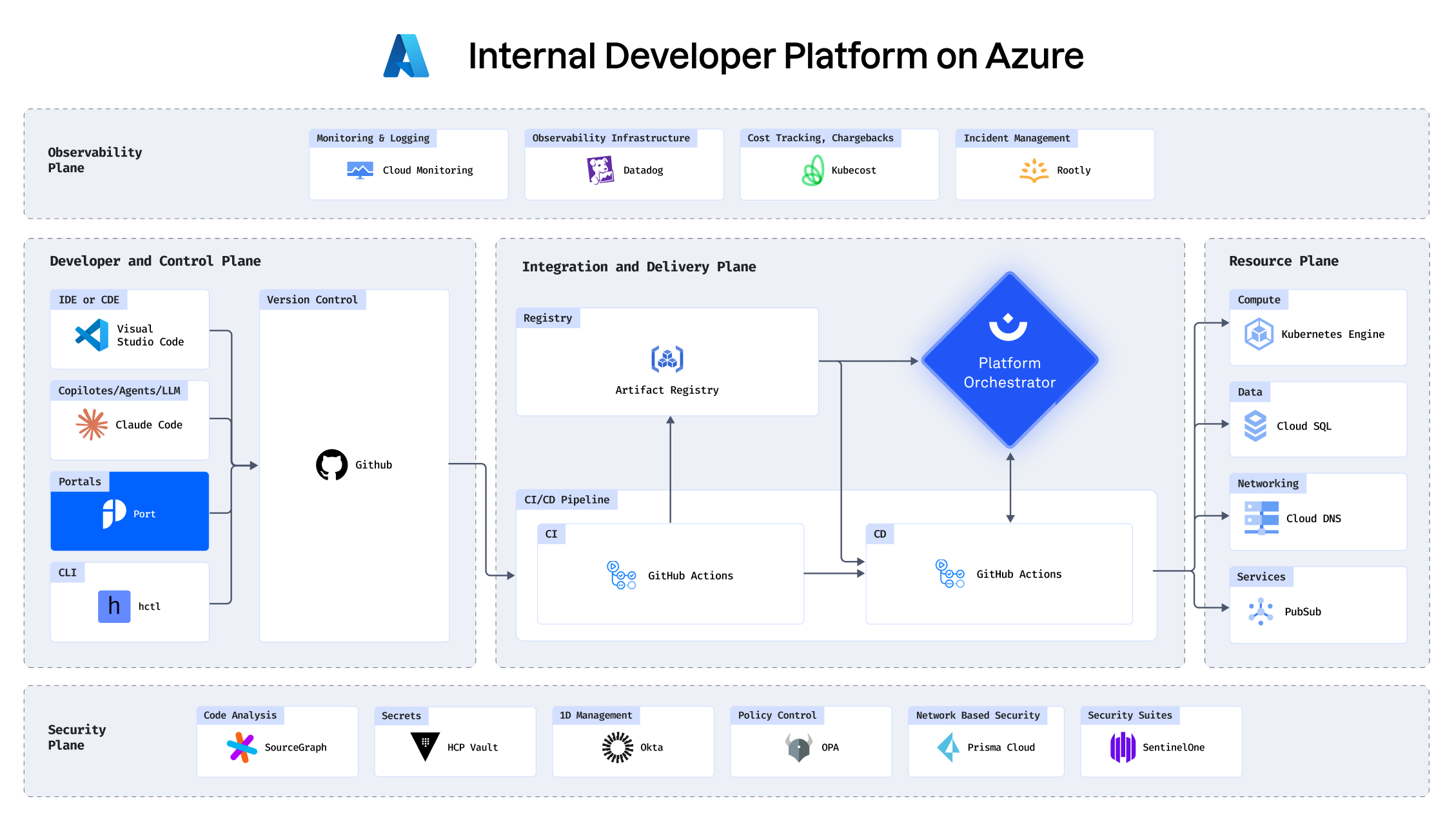
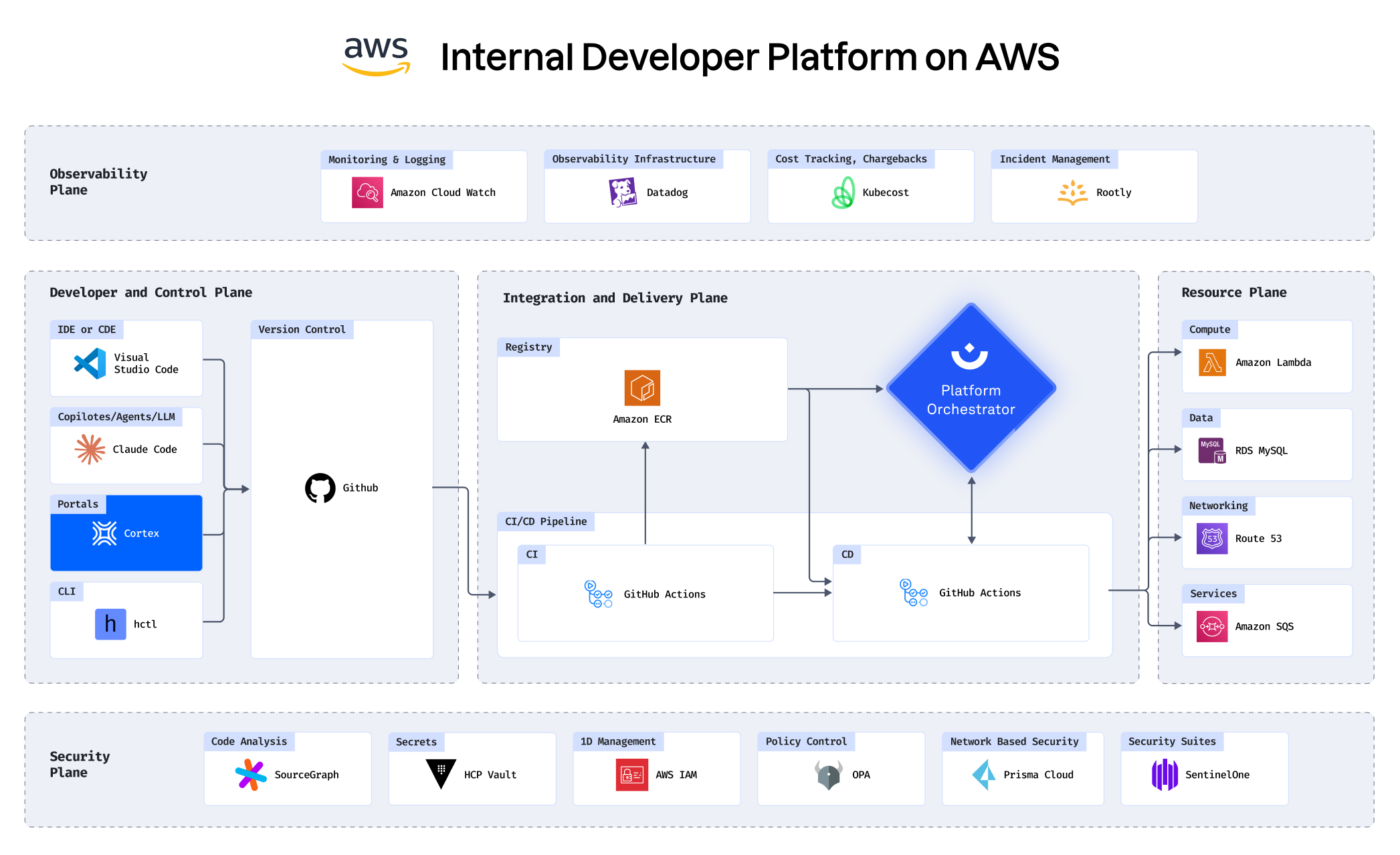
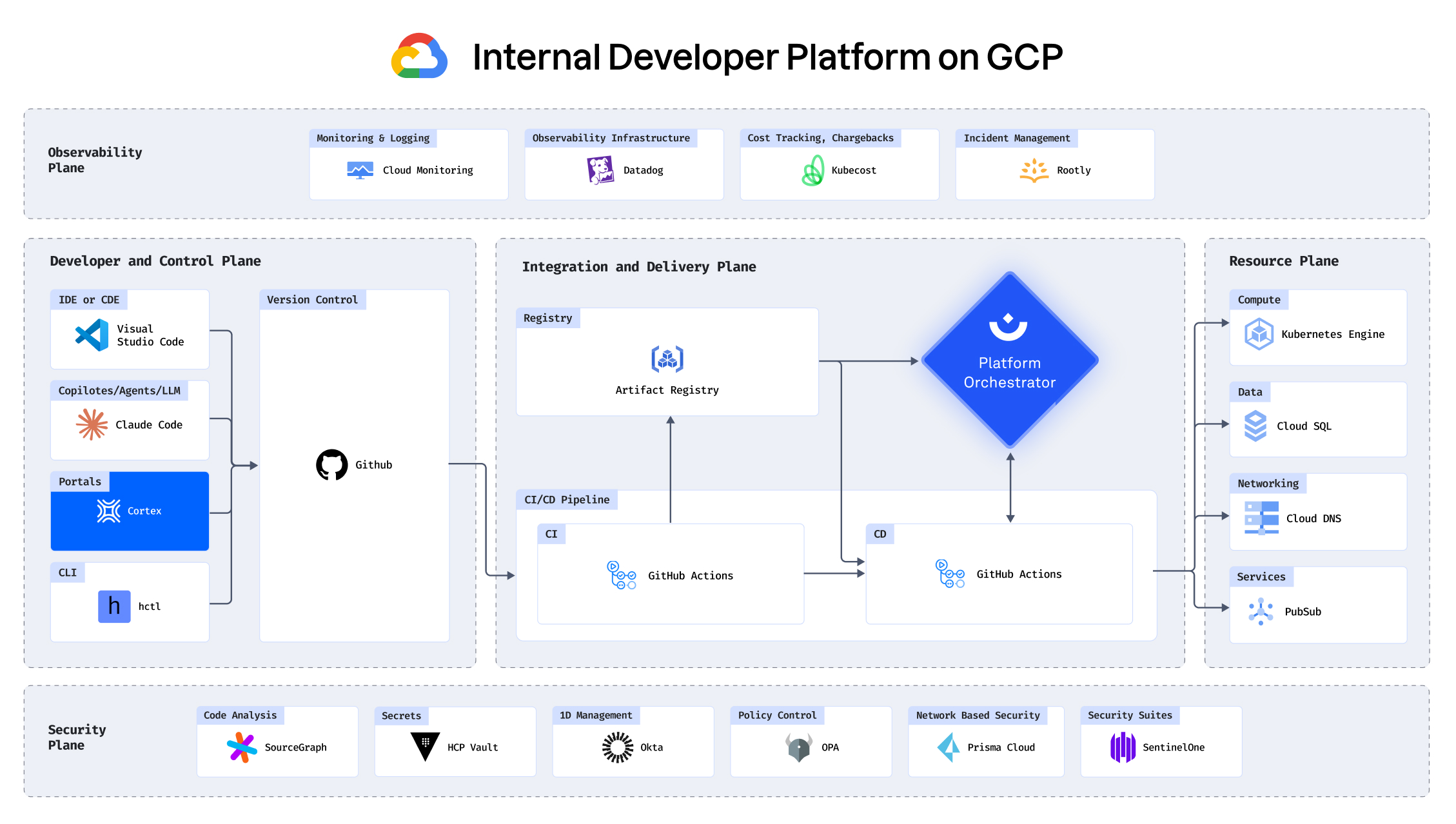
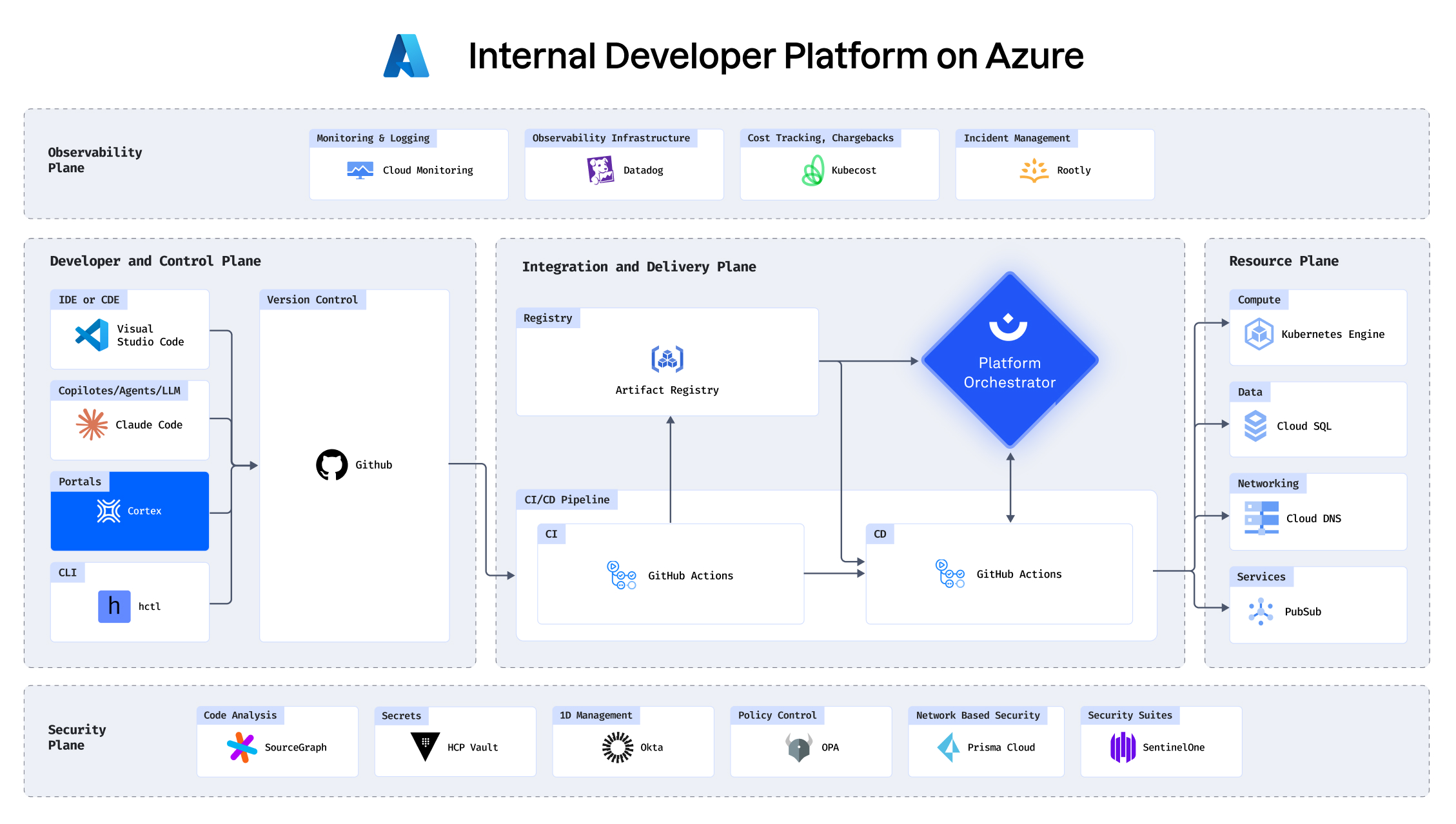
With your infrastructure on:


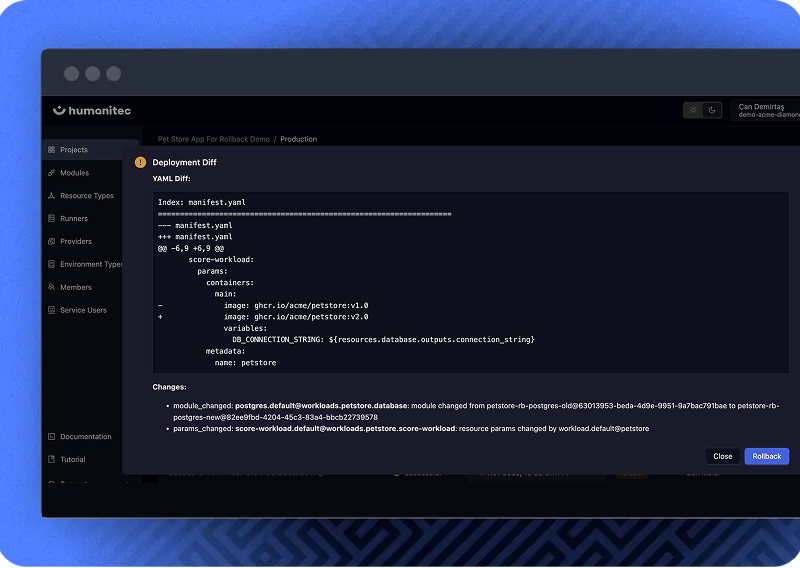
Know exactly what you’re rolling back
The Orchestrator shows a precise diff of what will update, letting you roll back with full confidence.

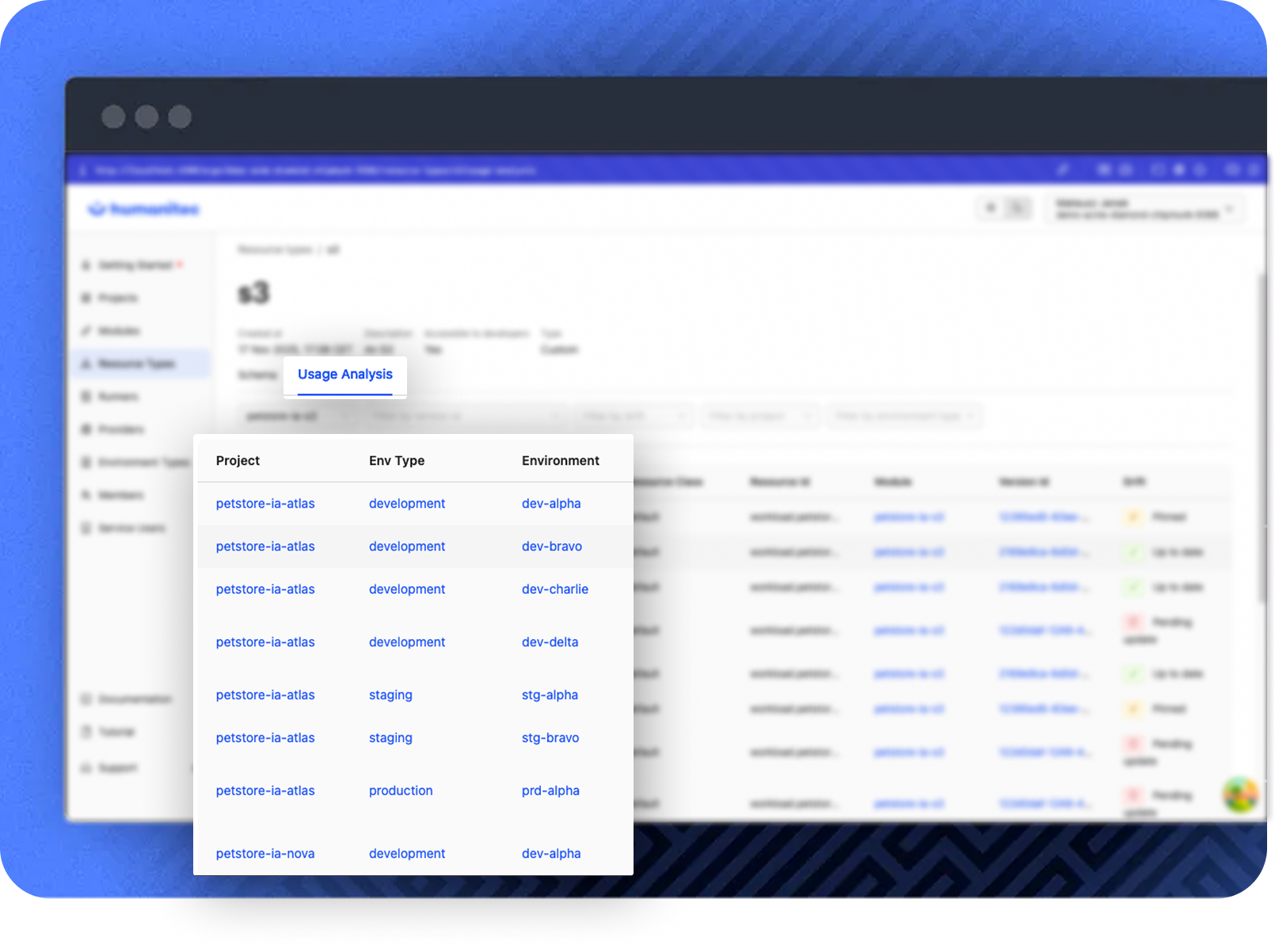
No more guessing who’s affected
When an incident hits, the Platform Orchestrator maps the issue across your infrastructure instantly. See which environments are at risk and which teams need to act.

HOW IT WORKS
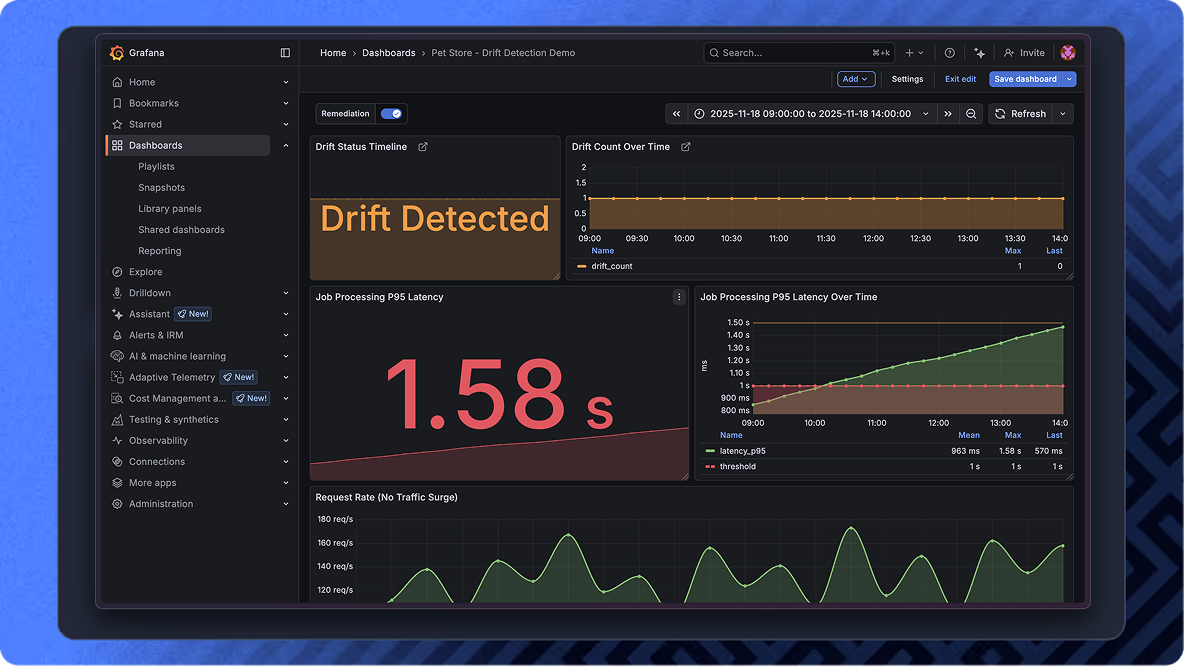
See drift. Understand it. Fix it.
Catch drift where you already monitor your systems
The Orchestrator surfaces drift into your existing
observability stack, so teams see issues
immediately.
observability stack, so teams see issues
immediately.

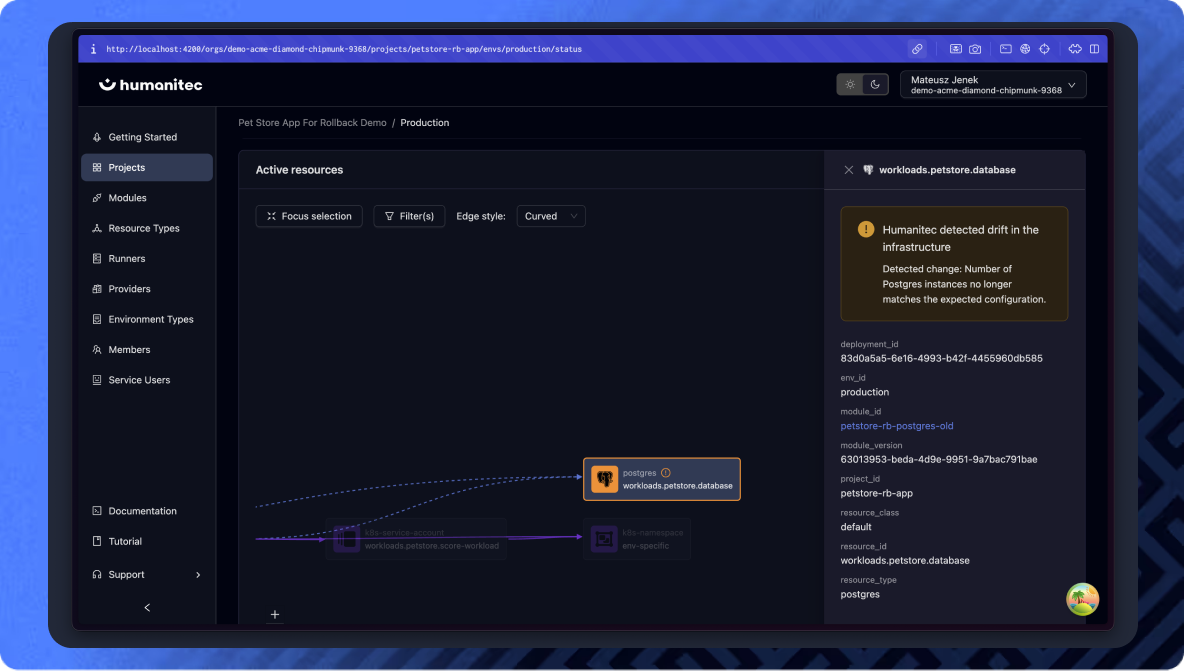
Know exactly what’s affected
The Orchestrator shows which workload and
environment are out of alignment
environment are out of alignment
See precisely what changed
Drill into the resource graph to identify the exact
node and configuration causing the drift, so teams
can resolve the issue fast and confidently.
node and configuration causing the drift, so teams
can resolve the issue fast and confidently.
Today
Drift goes unnoticed until it breaks something. A service misbehaves, a policy stops applying, or an audit reveals that production no longer matches its declared config. Teams scramble to figure out what changed, when it changed, and how to get back to a compliant state. The investigation takes longer than the fix while damage is being incurred.
vs
with Humanitec
Drift is caught right after it happens. Teams get an alert and restore the approved configuration with a single redeploy. No surprises, no compliance gaps, no late-night debugging. Environments stay secure and aligned by default.
Want to see how drift detection would work in your setup?
Today
A deployment breaks. Alerts fire. Developers ping platform engineers on Slack and create tickets. Someone digs through past deployments, figures out which version was stable, reverts the application, then manually aligns infrastructure to match. It is slow, stressful, and different every time.
vs
with Humanitec
A deployment breaks. The developer opens the Humanitec Platform Orchestrator and identifies the last known good deployment. With a single click on “Rollback”, the Orchestrator restores both the app and its infrastructure to that stable version in a single operation. No painful aligning of app components. Incidents are resolved in minutes, not hours.
Want to see how rollbacks would work in your setup?
Today
A bad module or configuration is discovered. No one knows how many environments it touches. Teams check repos manually, trace module versions by hand, or ping each other on Slack to piece together where the risk is. Hours are lost hunting for answers before any fix can even begin. Meanwhile, production might be exposed.
vs
with Humanitec
The moment a problem is identified, the Platform Orchestrator shows exactly which workloads and environments depend on the faulty version. Teams see the full blast radius instantly and can roll out fixes or forced updates with confidence. No investigation. No uncertainty. Just a controlled, transparent path to remediation.
Want to see how you’d identify affected environments when things go wrong?
Today
Infra updates go out all at once or rely on manual coordination. Teams hope nothing breaks. If something does, it’s unclear how far the damage spreads, and rolling back is slow and stressful.
vs
with Humanitec
Updates roll out in controlled waves. Start small, validate, then promote. You see exactly where the new version is live, stop anytime, and roll back an environment instantly without affecting the rest.
Want to see how you’d fix issues without a big-bang rollout?
See how you can build an IDP in under 30 minutes
Building an IDP using GCP, Port, Humanitec, Datadog and
more
Building an IDP using AWS, Cortex, Humanitec, Datadog and
more
See how you can enable developer self service in 5 minutes:
Dive deeper
No items found.