

If you've worked with banks, insurance companies, government agencies, or defense contractors, you know their deployment requirements differ fundamentally from a typical cloud-native setup. Air-gapped networks, multiple data centers across regulatory zones, strict data residency laws, PCI compliance—these aren't edge cases. They're the baseline.
The result? Deployment complexity explodes. And the usual "just deploy to the cloud" advice doesn't apply.
In this post, I'll walk through how to architect platform engineering for these environments using the Humanitec Platform Orchestrator running on-premises. We'll use a real banking scenario to demonstrate the approach: a payments ledger application that needs to run across five different environments with wildly different compliance requirements.
The Problem: Same Application, Five Different Deployment Realities
Let's look at a representative setup from the banking sector. We have a payments ledger application—it processes financial transactions and account data. The kind of data you absolutely cannot have falling into the wrong hands.
This application needs to run across five environments:
- Dev: Isolated development network with mock data, running in a shared Kubernetes cluster on GKE
- QA: Staging environment that mirrors production data and security grades for representative testing
- Prod-DC1: Primary production data center in New York, strictly PCI compliant
- Prod-DC2: Secondary production data center in London, subject to different data residency laws
- DR-Cloud: Disaster recovery site, air-gapped, running on GCP for regulatory requirements
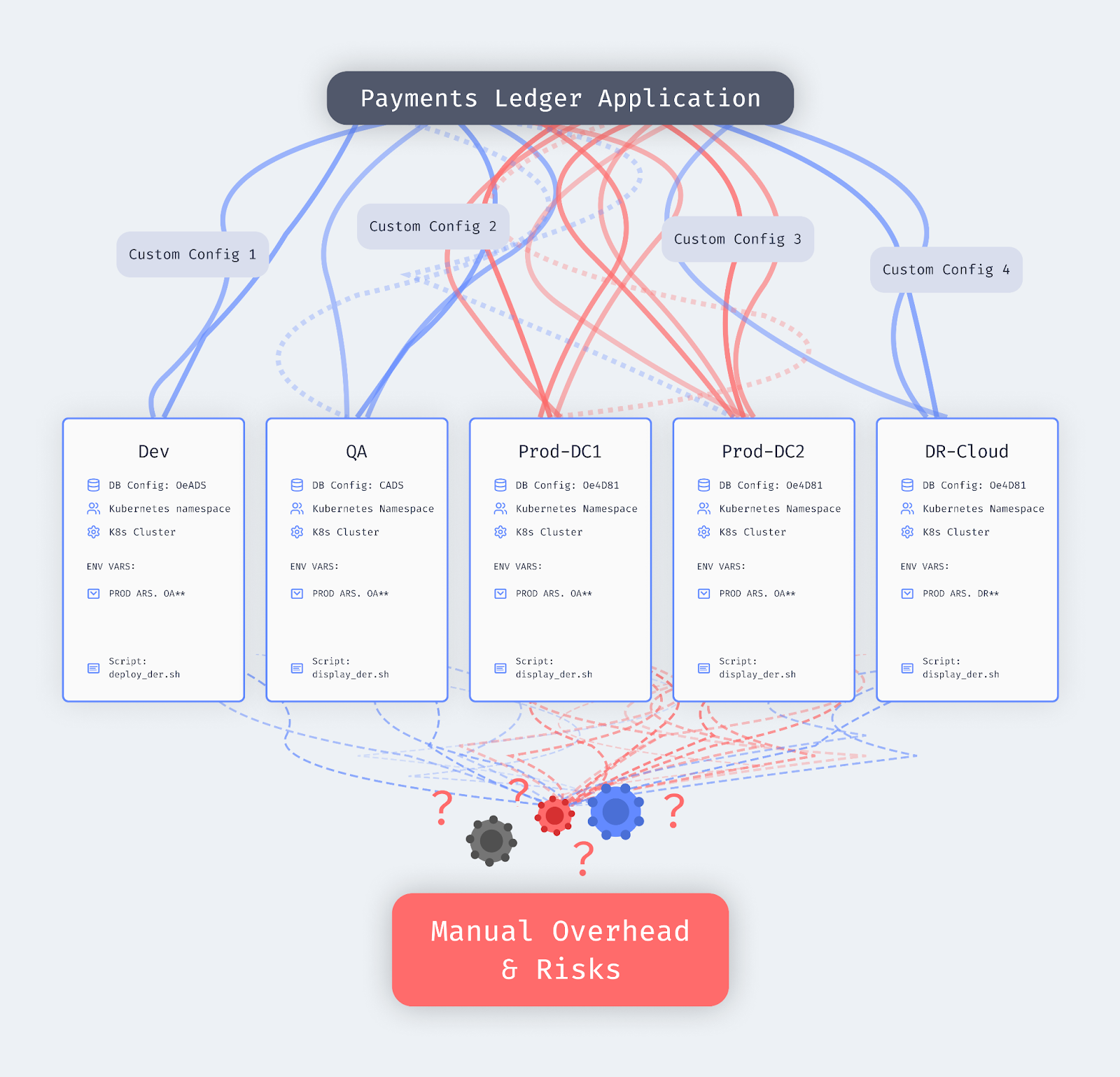
Each environment needs different database configurations, security policies, and network settings. All of these configurations have to be stored somewhere, for every single workload, every single resource, in every single environment. You can do the math, that's a lot of files to maintain.
Here's what this means in practice:
For developers: They need separate manifests for each environment, different application configurations, different deployment scripts. Any change to the target infrastructure requires talking to someone else and waiting.
For operations: Configuration drift between environments leads to production failures, outages, and security incidents. Compliance audits become nightmares when you need to prove that dev matches staging matches prod, and document who deployed what changes where.
For the organization: Disaster recovery testing requires completely different deployment procedures. Spinning up a new environment means custom configurations and setup work. Everything takes longer than it should.
The core pain point: the same application code, the same artifact, needs essentially five different ways to deploy it. That's where complexity scales, standardization breaks down, and security becomes a governance problem.
The Solution: A Rules Engine Between Developers and Infrastructure
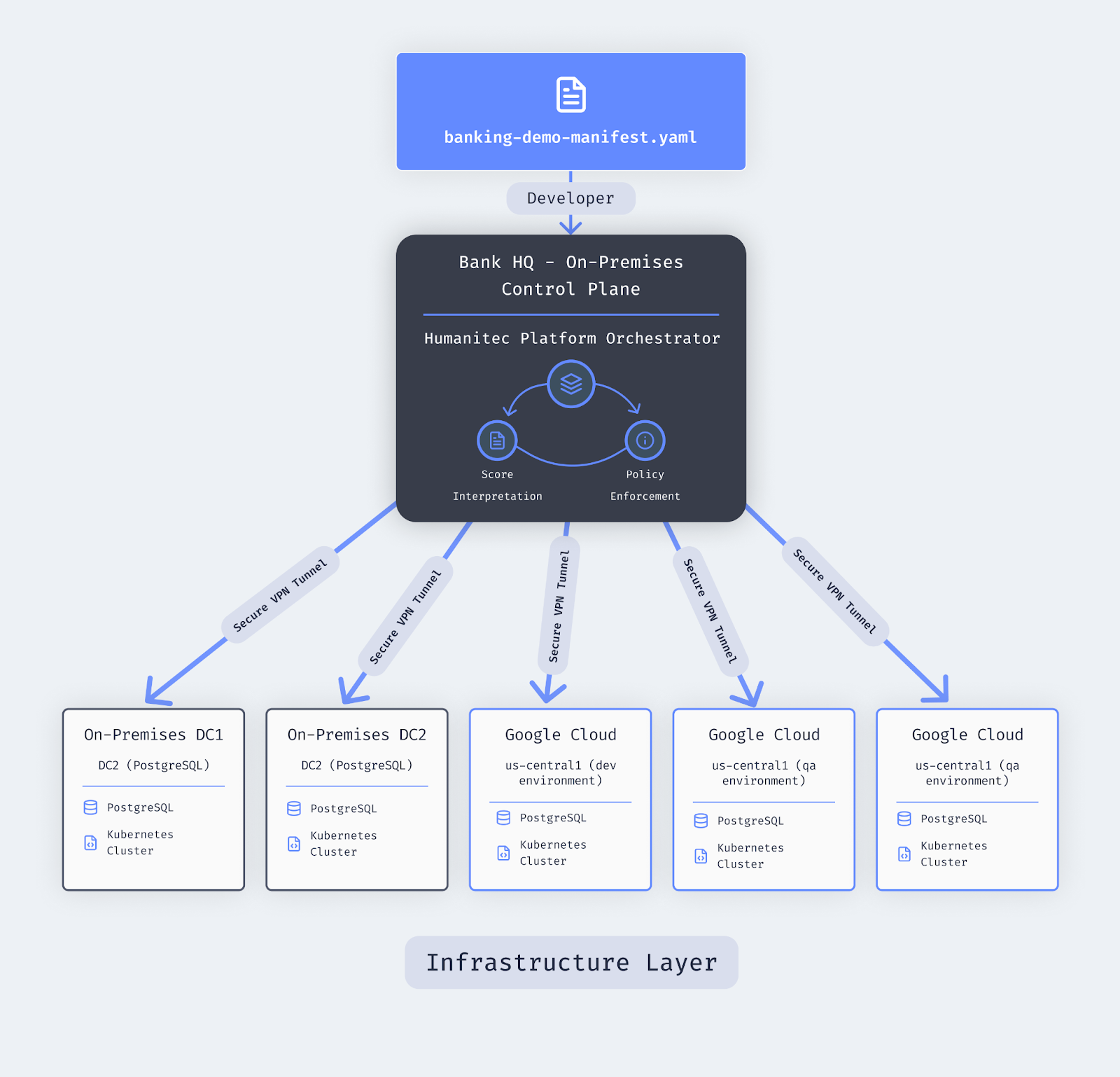
The architecture that solves this puts the Platform Orchestrator between developers and the actual infrastructure rules. Rather than dealing with many configurations, developers work with a single manifest file.
Here's what a manifest file looks like for the payments ledger:
shared:
- type: postgres
class: default
workloads:
payments-ledger-service:
containers:
main:
image: payments-ledger:latest
variables:
DB_CONNECTION_STRING: ${resources.postgres.outputs.connection_string}
resources:
- type: namespace
- type: k8s-service-account
Notice what's missing: there are no environment-specific configurations. No localization to dev or the different production environments. Developers describe what the payments ledger service needs that holds true across all environments—a Postgres database, a namespace, a service account.
The orchestrator acts as a rules engine. It takes that manifest and localizes the configurations to fit exactly the regulatory and compliance needs of each target environment. Platform engineers configure the rules; developers consume them without needing to understand the underlying complexity.
What the Orchestrator Actually Produces: Two Concrete Examples
From the developer’s perspective, nothing changes—they still submit the same manifest. But under the hood, the Platform Orchestrator resolves that intent very differently depending on the target environment.
Let’s look at two examples of what the resulting configuration might look like after the orchestrator applies environment-specific rules.
Example 1: Dev Environment (GKE, Shared Cluster)
In the Dev environment, the goal is speed and cost efficiency. Security controls exist, but they’re lighter, and managed cloud services are acceptable.
The orchestrator might resolve the postgres dependency like this:
- Database: Managed Cloud SQL (Postgres)
- Authentication: GCP Workload Identity
- Network: Shared VPC, non-production subnet
- Backups: Daily snapshots
- Data: Synthetic or masked data only
Conceptually, the resolved configuration could look like:
postgres:
type: gcp-cloudsql
version: "14"
instance_class: db-custom-2-7680
network: shared-dev-vpc
backup_policy:
frequency: daily
auth:
method: workload-identity
Example 2: Production (NYC Data Center, PCI-Compliant)
Now contrast that with Prod-DC1, where regulatory and security requirements dominate every decision.
Here, the same postgres requirement is resolved very differently:
- Database: Self-managed Postgres cluster on dedicated VMs
- Authentication: Short-lived credentials issued by Vault
- Network: Isolated PCI network segment
- Encryption: FIPS-compliant encryption at rest and in transit
- Auditing: Full query and access logging
The orchestrator might translate the same intent into something like:
postgres:
type: onprem-postgres
topology: active-passive
storage:
encrypted: true
encryption_standard: FIPS-140-2
network:
segment: pci-prod-nyc
credentials:
source: vault
ttl: 15m
audit:
enabled: true
log_destination: siem
The application sees the same interface—a connection string injected as an environment variable—but the underlying implementation meets strict PCI and regional compliance requirements.
Why On-Premises Matters
This is where the architecture differs fundamentally from a typical SaaS setup. The Platform Orchestrator v2 is compute-agnostic and runs on your network—in your data center or cloud account, self-hosted.
This matters for two reasons:
No network traffic in or out. In high-security environments, you cannot have deployment orchestration happening through external services. From a security perspective, orchestration systems can be perfect attack vectors for supply chain attacks. By hosting the orchestrator on your own premises, all traffic stays contained within your controlled networks.
Secure connections to targets. The orchestrator connects to your different environments—clouds, data centers, Kubernetes clusters—through secure VPN tunnels. It reads the manifest, analyzes the default configs provided by platform and infra teams, generates environment-specific configurations, and deploys to DC1, DC2, your cloud environments, wherever needed.
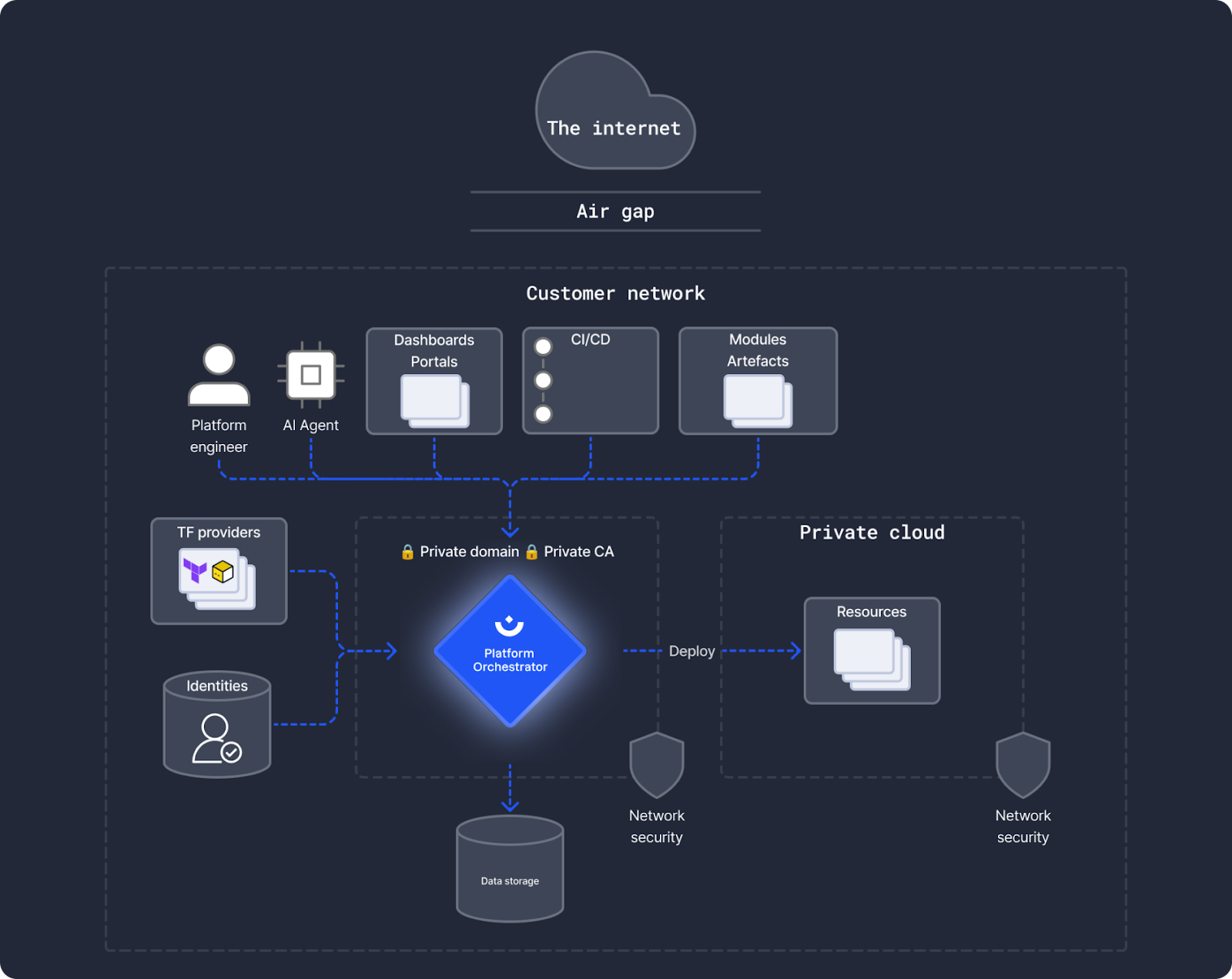
Two Personas, Zero Handoffs
The architecture creates clear separation between two persona groups who don't need to constantly coordinate:
Developers stay in their IDE and CI/CD workflows. They request deployments, specify that they need resources like a Postgres database or S3 bucket, and deploy to target environments. The orchestrator creates everything, provides outputs to the CI/CD system, and handles the infrastructure complexity.
Platform engineers configure the orchestrator. They define the Terraform modules that specify how Kubernetes namespaces get configured in the New York data center. They set the compliance and regulatory rules. They build the menu of resource types developers can request—databases, buckets, DNS, namespaces, lambdas, GPU compute, whatever the organization needs.
The orchestrator combines these inputs and ensures that every deployment produces 100% standardized, structured configurations for exactly the target environment.
Demo: Adding an S3 Bucket Across Environments
Let's see this in practice. A developer wants to add an S3 bucket to the payments ledger service across different environments.
In the traditional world, this means filing a ticket, waiting for operations to provision the bucket environment by environment, security review, and a few days later you might have your S3 bucket.
With the orchestrator, the developer adds this to the manifest:
shared:
- type: s3
id: document-storage
class: default
workloads:
payments-ledger-service:
variables:
DOCUMENT_STORAGE_BUCKET: ${resources.document-storage.outputs.bucket_name}
DOCUMENT_STORAGE_REGION: ${resources.document-storage.outputs.region}
The class parameter lets platform teams offer options—private, public, small, large, whatever makes sense for the organization. Here we're using the default.
Deploy to dev:
hctl deploy payments-ledger --env development --manifest ./manifest.yaml
The orchestrator receives this, determines what rules and configurations the infrastructure team has defined for S3 buckets in development, spins up the bucket, and wires it to the workload. Seconds later, done.
Deploy to QA with the exact same manifest:
hctl deploy payments-ledger --env qa --manifest ./manifest.yaml
Same file, different target. The orchestrator applies the QA-specific rules—maybe different security policies, different network configuration, different underlying infrastructure—and deploys. The developer never needs to know how S3 buckets differ between dev and QA. They specify what they need; the platform ensures it's configured correctly for each target.
How the Orchestrator Knows What to Do
Platform engineers configure this through resource types and matching rules. In the Platform Orchestrator UI (though everything is backed by code), you define:
Resource types: The menu of what developers can request. Buckets, DNS, namespaces, lambdas, databases—whatever your organization provides.
Modules: The matching rules that determine when to use what. "If someone deploys to a development environment, use this shared Kubernetes cluster. Here's the source to the infrastructure-as-code." This is how the orchestrator knows when to use which resource, how to inject variables, how to configure for compliance.
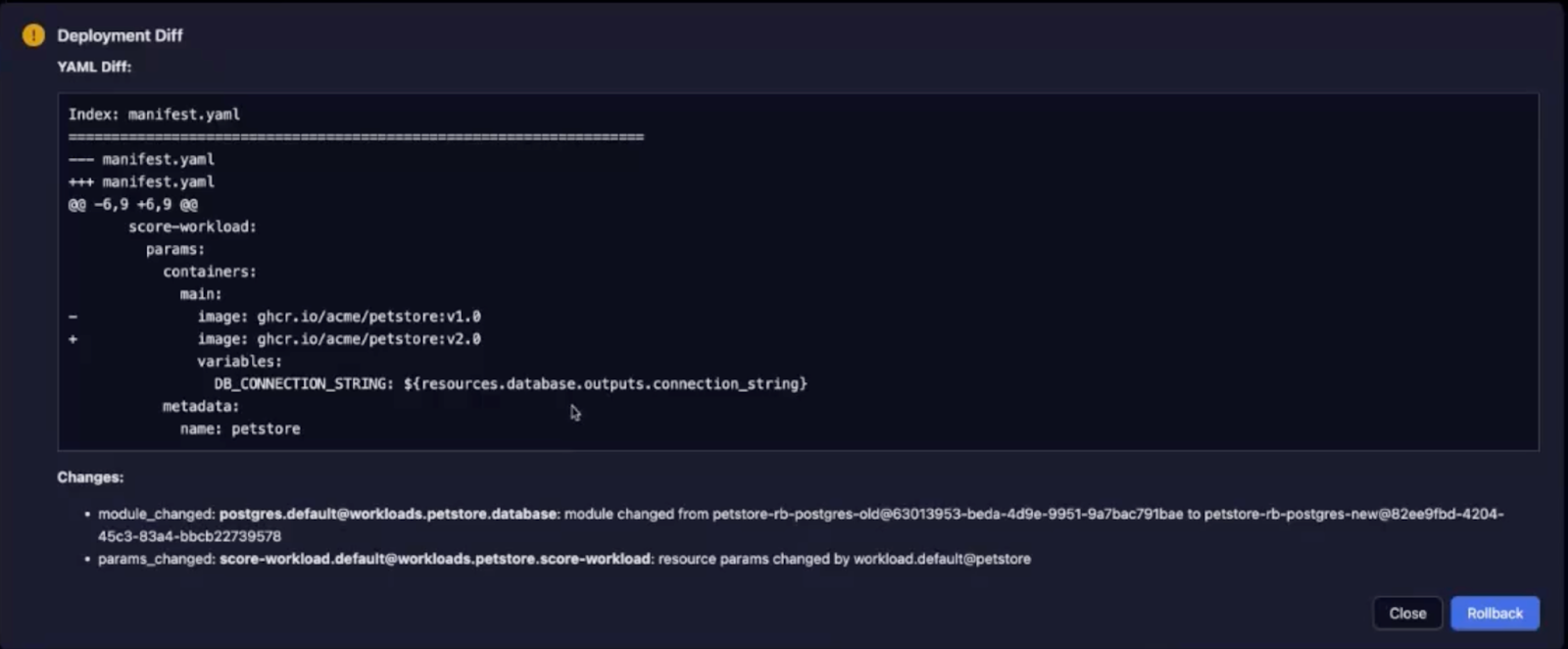
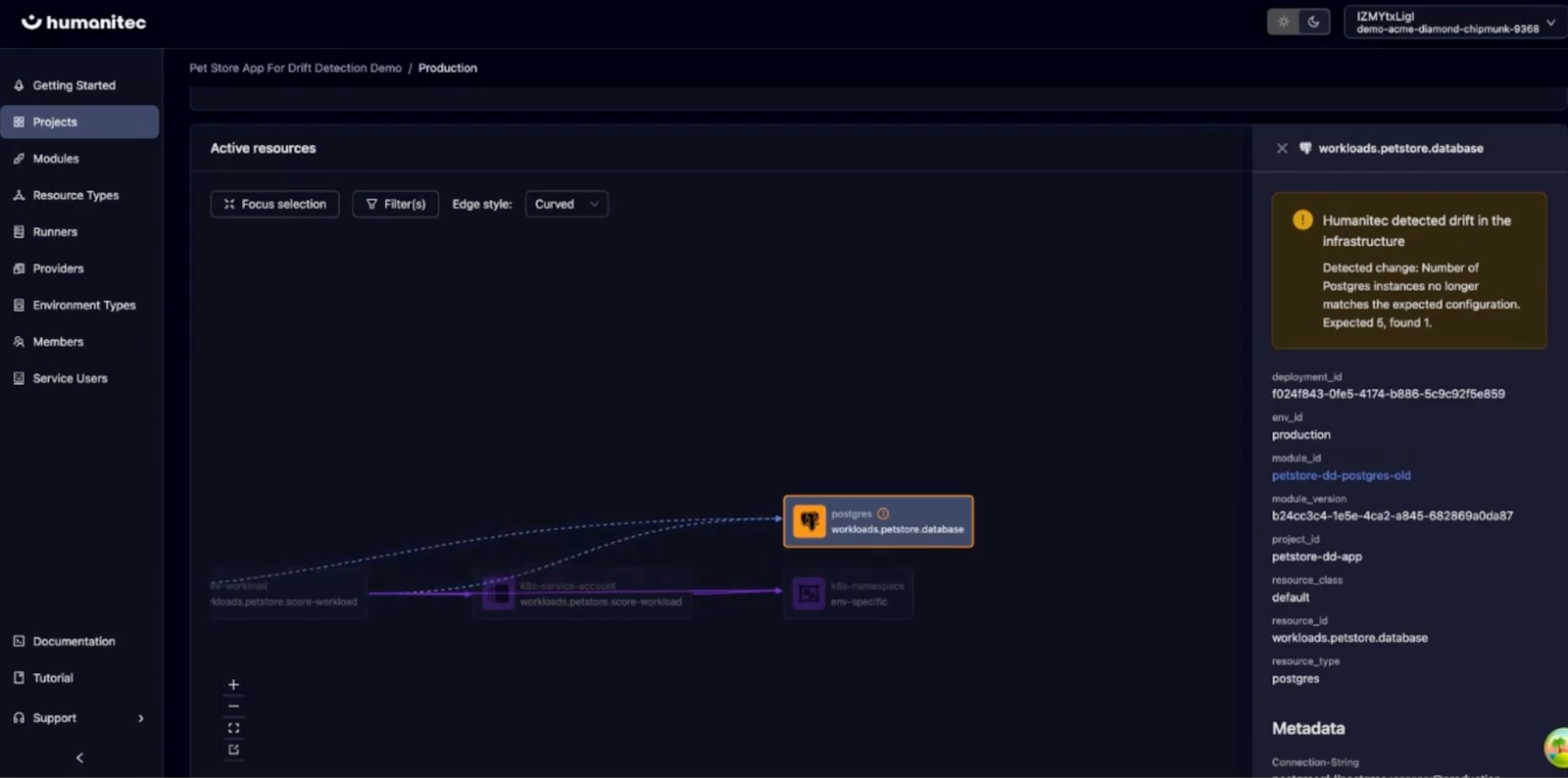
Drift Detection and Remediation
Because the orchestrator maintains a model of what should be running, you can detect when reality diverges from configuration.
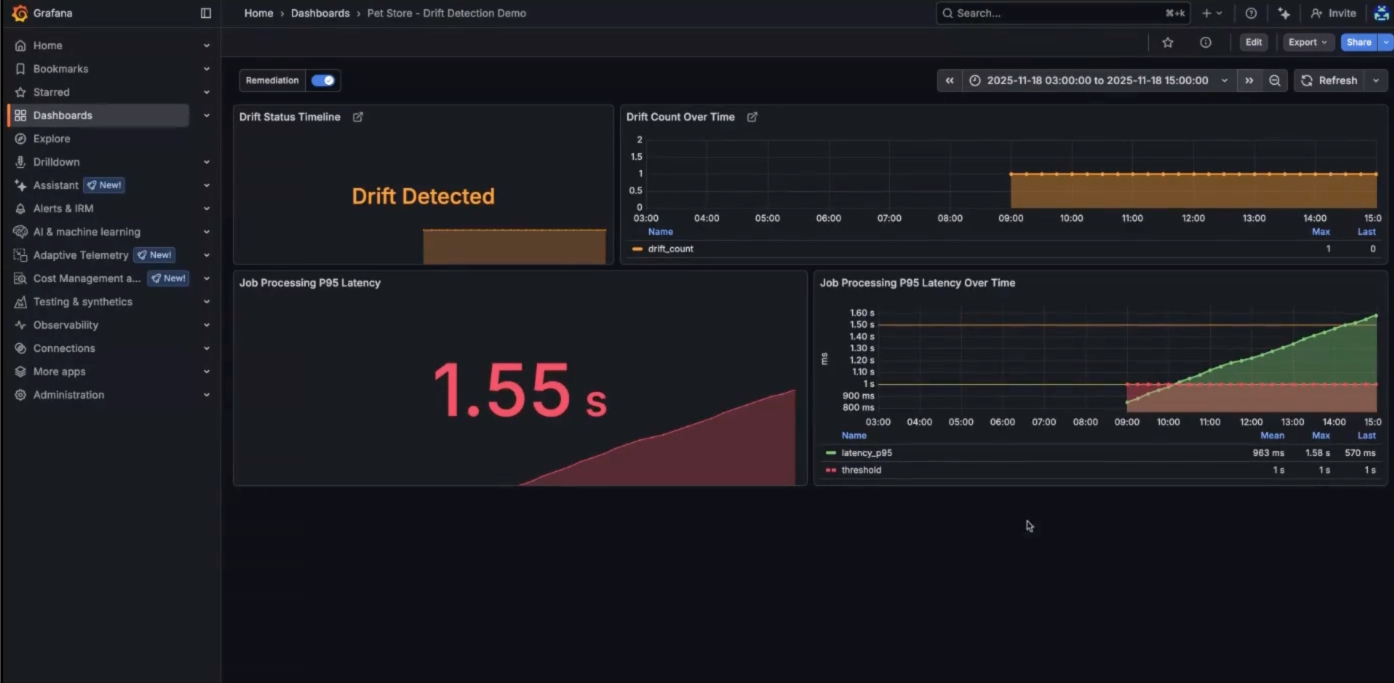
Wire the orchestrator's API to your observability tooling and you can flag drift in real-time. If someone gains access to your data center and changes configs manually, or if infrastructure drifts for any reason, the system detects the discrepancy between the policy-compliant configuration in the orchestrator and the running system.
From there, you can remediate immediately—the resource graph shows the drift, and you can take action to restore the correct state.
This also enables point-in-time rollbacks that include both application and infrastructure configuration as one unit. When you're resolving an incident at 3am, that capability matters.
What This Delivers
For a banking application like the payments ledger across five environments with hybrid infrastructure and complex compliance requirements:
Speed: Deploy to all five environments in minutes instead of weeks of coordination.
Single source of truth: One manifest eliminates configuration drift. Developers focus on business logic, not infrastructure differences.
Cost reduction: Eliminate weeks of infrastructure coordination. Reduce deployment failures and production incidents. Scale development velocity without scaling operations overhead.
Compliance and governance: Consistent policy enforcement across all environments. The on-premises orchestrator keeps sensitive decisions within the bank's network. Full audit trail for all deployment changes.
Risk mitigation: No configuration drift between environments. Automated compliance checks before production. Standardized deployment patterns across hybrid infrastructure.
The bottom line: same application definition, platform handles hybrid complexity—from cloud development to on-premises production to disaster recovery. Deploy once, run everywhere, stay compliant.
We have prepared a video version of this including a demo walk through, check it out!
Try It Yourself
You can test the SaaS version of the Platform Orchestrator through our 10-minute sandbox experience—no cloud accounts required.
For the on-premises version suitable for high-security environments like banking, insurance, government, or defense, get in touch with us. We'll help you set it up, test it, and take it from there.
